

2026.05.15 / 동준상.넥스트플랫폼
(AWS SAA, AWS AIF, GCP GenAI Leader)
Mastering LLM Memory Optimization with TurboQuant: Core Concepts & Top 5 Case Studies
TurboQuantによるLLMメモリ最適化の本質:基本概念と実証プロジェクトTOP5
핵심 정리 (Executive Summary)
이번 포스트에서는 TurboQuant 기술을 활용한 거대언어모델(LLM) 메모리 최적화 기법의 개념에 대해 알아보고, 핵심 기술 개념을 실증할 수 있는 5가지 ‘바이브코딩(Vibe Coding)’ 프로젝트를 소개합니다.
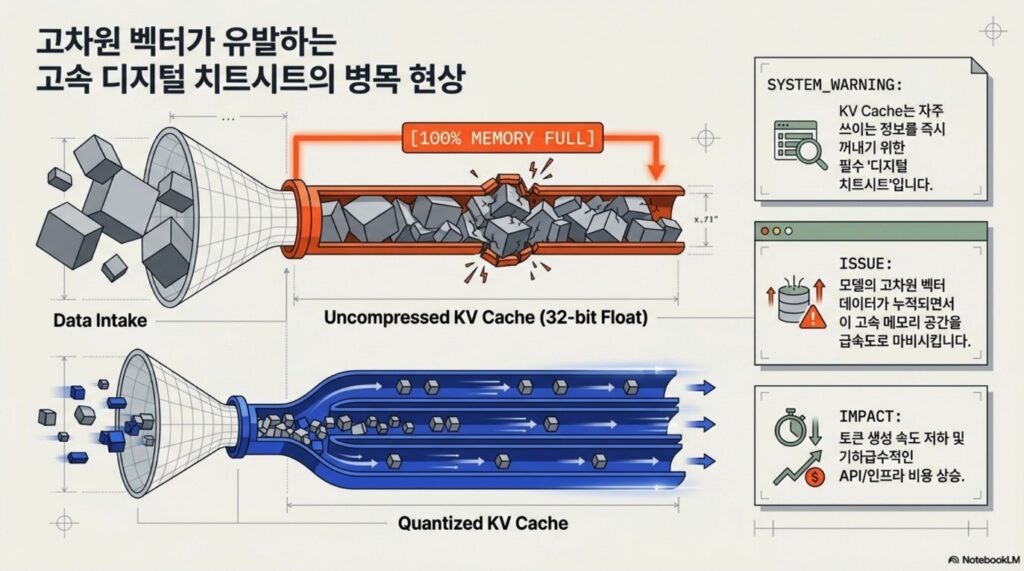
- TurboQuant는 KV 캐시(Key-Value Cache) 압축, 벡터 양자화, PolarQuant의 극좌표 변환 기술을 결합하여 LLM 운영의 주요 문제인 메모리 비용과 병목 현상에 대한 해법으로 주목 받음
- 실증 연구에서 TurboQuant는 4비트 수준에서 메모리 사용량을 6배 이상 절감하면서도 모델의 정확도를 유지하며, 별도의 훈련이나 파인튜닝 없이도 원본 LLM보다 빠른 런타임을 구현할 수 있음을 증명
- TurboQuant의 핵심적인 기술 개념을 반영한 5가지 프로젝트를 이용하여 LLM 시대에 수요가 폭증한 메모리 최적화에 대한 실증, 교육, 비즈니스 진단, 실무형 프로토타입 제작 등 다각적으로 활용
1. LLM 메모리 최적화 기법으로서 TurboQuant의 주요 기술 개념
TurboQuant는 LLM의 효율적인 운영을 위해 다음과 같은 세 가지 핵심 아이디어를 기반으로 한다.
- KV 캐시 압축: 자주 사용되는 정보를 즉시 호출할 수 있도록 저장하는 고속 ‘디지털 치트시트’인 KV 캐시의 고차원 벡터 데이터를 압축하여 메모리 정체를 해소한다.
- 벡터 양자화 (Vector Quantization): 데이터를 32bit에서 8bit, 4bit, 심지어 3bit까지 축소하여 저장 공간을 줄인다. 이는 메모리 비용 절감과 직결된다.
- PolarQuant (극좌표 변환): 데이터를 표준 직교 좌표(Cartesian)가 아닌 극좌표(Polar)로 변환하여 표현한다. 이는 양자화 과정에서 발생하는 경계 오버헤드를 제거하고 정확도 손실을 최소화하는 혁신적인 접근법이다.
2. TurboQuant 실험 프로젝트 TOP5
2.1. LLM 메모리 비용 시뮬레이터
- 목적: 사용자가 API 호출 시 발생하는 KV 캐시의 메모리 점유율과 양자화에 따른 비용 절감 효과를 수치로 체감하게 함.
- 주요 기능:
- 모델명, 컨텍스트 길이, 레이어 및 헤드 수 입력.
- 32bit 대비 8/4/3bit 양자화 수준별 메모리 사용량 계산.
- 비트폭별 메모리 절감률 및 월간 API 비용 절감 추정치 시각화.
- 비즈니스 가치: 양자화 도입의 경제적 타당성을 설득하는 오프닝 시연 도구로 적합함.
2.2. 임베딩 압축 전후 유사도 검색 비교 앱
- 목적: 양자화가 검색 정확도에 미치는 영향이 미미함을 직접 검증함.
- 구현 방식:
sentence-transformers를 이용한 float32 임베딩 생성.numpy를 활용한 int8/int4 수동 양자화 적용.- 원본과 양자화 임베딩 간의 Top-K 검색 결과 및 Recall@K 비교.
- 핵심 가치: 4비트 수준에서 6배 메모리 절감과 동시에 “손실 없는” 압축을 실증함.
2.3. PolarQuant 시각화 교육 앱
- 목적: 직교 좌표계와 극좌표계의 차이를 시각화하여 PolarQuant의 기술적 우위를 교육함.
- 시각화 요소:
- 2D 벡터의 좌표 변환 과정 인터랙티브 애니메이션.
- 정사각형 그리드(Cartesian)와 원형 그리드(Polar) 비교를 통한 경계 오버헤드 제거 원리 설명.
- 비트수 조절에 따른 양자화 오차 실시간 변화 시뮬레이션.
2.4. 미니 시맨틱 검색 엔진 (with 양자화)
- 목적: 양자화된 벡터 인덱스를 기반으로 한 고성능 RAG(검색 증강 생성) 프로토타입 구축.
- 기술 스택: Next.js, Neon PostgreSQL, pgvector.
- 기능:
- 문서 업로드 및 int8 양자화 임베딩 저장.
- Full Precision과 양자화 벡터 경로의 동시 검색 및 결과 비교 대시보드.
- 빠른 전처리 시간과 높은 정확도 유지 확인.
2.5. LLM 운영 최적화 진단 대시보드
- 목적: 특정 서비스 환경에 최적화된 양자화 비트폭을 추천하는 비즈니스 컨설팅 도구.
- 입력 변수: 서비스 유형(챗봇/RAG/요약), 일일 요청 수, 평균 컨텍스트 길이, 허용 가능한 정확도 손실률.
- 출력 결과: 권장 비트폭, 예상 메모리 및 비용 절감 시나리오(보수적/균형/공격적), Ollama 적용 가이드 자동 생성.
FAQ: TurboQuant 기반 LLM 메모리 최적화
Q1. 실제 비즈니스나 서비스에 어떻게 응용할 수 있나요?
A5. 미니 시맨틱 검색 엔진 구축 시 벡터 인덱스를 양자화하여 RAG(검색 증강 생성) 운영 메모리를 절반으로 줄일 수 있습니다. 또한, 서비스 유형(챗봇, 요약 등)에 따른 최적의 양자화 비트폭을 진단하고 비용 절감 시나리오를 도출하는 대시보드 형태로 구현하여 운영 효율을 높일 수 있습니다.
Q2. KV cache 양자화가 왜 중요하며, 어떤 효과가 있나요?
A2. KV cache는 자주 쓰이는 정보를 즉시 꺼낼 수 있도록 저장하는 고속 “디지털 치트시트” 역할을 하지만, 많은 메모리를 점유합니다. 데이터를 32bit에서 8bit, 4bit, 심지어 3bit까지 양자화하면 메모리 사용량을 획기적으로 줄일 수 있으며, 이는 월간 API 비용 절감으로 직결됩니다.
Q3. PolarQuant란 무엇이며 기존 방식과 어떻게 다른가요?
A3. PolarQuant는 데이터를 표준 직교 좌표(X, Y, Z) 대신 **극좌표(방향과 거리)**로 변환하여 표현하는 기술입니다. 이를 통해 양자화 그리드를 사각형에서 원형으로 바꾸어 경계 오버헤드를 제거하고, 양자화 오차를 줄이면서 효율적으로 데이터를 압축할 수 있습니다.
Q4. 양자화를 적용하면 모델의 성능이나 정확도가 떨어지지 않나요?
A4. TurboQuant의 큰 장점 중 하나는 별도의 추가 훈련이나 파인튜닝 없이도 KV cache를 3비트까지 양자화할 수 있다는 점입니다. 이를 통해 모델 정확도 손실 없이 원본 LLM보다 오히려 더 빠른 런타임 속도를 달성할 수 있습니다.
결론
- TurboQuant 기술은 LLM의 하드웨어 요구사항을 획기적으로 낮추면서도 성능을 유지할 수 있는 실질적인 해법을 제시한다.
- 바이브코더는 복잡한 기술적 개념을 시각화하고 실질적인 비용 절감 수치로 변환함으로써, 기술 도입의 장벽을 낮추고 교육 및 비즈니스 현장에서 즉각적인 가치를 창출할 수 있다.
- 특히 1번 메모리 비용 시뮬레이터와 3번 시각화 앱은 기술적 이해도를 높이는 데 매우 강력한 도구가 될 수 있다.
참고자료 및 다운로드
슬라이드 | TurboQuant LLM Memory Optimization by NextPlatform
https://drive.google.com/file/d/1ey3eHehlx0Qor3G6VbckHN_hYRMy0wPs/view?usp=sharing
바이브코딩 프로젝트 핸드북
TurboQuant가 실증한 KV cache 압축, 벡터 양자화, PolarQuant의 극좌표 변환 아이디어를 기반으로 한 메모리 활용 방법 혁신 프로젝트
| 프로젝트명 | 예상 소요 시간 | 주요 활용처 |
| LLM 메모리 비용 시뮬레이터 | 30~45분 | 강연 오프닝 시연 (KPC AX 등) |
| PolarQuant 시각화 앱 | 60~90분 | 기술 강연 개론 및 원리 설명 |
| 임베딩 압축 비교 앱 | 60분 | 중급 과정 프로젝트 (Goorm 등) |
| 미니 시맨틱 검색 엔진 | 2~3시간 | 기술 데모 및 백엔드 확장 (AIGrape) |
| 최적화 진단 대시보드 | 90분 | 뉴스레터 콘텐츠 및 비즈니스 진단 |
1️⃣ LLM 메모리 비용 시뮬레이터
“내 API 호출이 KV cache를 얼마나 잡아먹는가”
핵심 아이디어: KV cache는 자주 쓰이는 정보를 즉시 꺼낼 수 있도록 저장하는 고속 “디지털 치트시트”인데, 고차원 벡터가 이를 막히게 한다. 이 병목을 사용자가 직접 느낄 수 있게 시각화하는 앱.
구현 방향 (Streamlit 또는 Next.js):
- 입력: 모델명, context 길이, 레이어 수, 헤드 수
- 계산: 32bit → 8bit → 4bit → 3bit 각 quantization 수준별 KV cache 메모리 사용량
- 출력: 비트폭별 메모리 절감률 + 월간 API 비용 절감 추정치 시각화
강연 활용도: ⭐⭐⭐⭐⭐ — KPC AX 강연에서 “왜 양자화가 비즈니스 문제인가”를 수치로 보여주는 오프닝 시연으로 즉시 활용 가능
2️⃣ 임베딩 압축 전후 유사도 검색 비교 앱
“압축해도 검색 정확도는 유지되는가?”
핵심 아이디어: TurboQuant는 4비트 수준에서 6배 이상 메모리를 줄이면서도 정확도 손실 없이 KV cache를 압축한다. 이 “손실 없음”을 사용자가 직접 체험하는 앱.
구현 방향 (Python + Streamlit):
sentence-transformers로 텍스트 임베딩 생성 (float32)numpy로 int8 / int4 수동 양자화 적용- 동일 쿼리에 대해 full precision vs. 양자화 임베딩의 Top-K 검색 결과 비교
- 정확도(recall@k)와 메모리 사용량을 나란히 표시
난이도: 🟡 응용 — sentence-transformers + numpy만으로 구현 가능
3️⃣ PolarQuant 시각화 교육 앱
“극좌표 변환이 왜 메모리 오버헤드를 없애는가”
핵심 아이디어: PolarQuant는 데이터를 표준 직교 좌표(X, Y, Z) 대신 극좌표로 변환한다 — “동쪽으로 3블록, 북쪽으로 4블록” 대신 “37도 방향으로 5블록”으로 표현하는 것과 같다.
구현 방향 (React + D3.js 또는 Plotly):
- 2D 벡터를 입력하면 직교 좌표 → 극좌표 변환 과정을 인터랙티브 애니메이션으로 표현
- 양자화 그리드가 “정사각형(Cartesian)”에서 “원형(Polar)”으로 바뀔 때 경계 오버헤드가 사라지는 것을 시각화
- 교육용 슬라이더: 비트수를 조절하면 양자화 오차가 실시간으로 변하는 시각화
강연 활용도: ⭐⭐⭐⭐ — 기술 강연의 “개론 B” 블록에서 15분 시각 설명 대체재로 활용
4️⃣ 미니 시맨틱 검색 엔진 with 양자화
“RAG를 절반 메모리로 운영하는 미니 프로토타입”
핵심 아이디어: TurboQuant는 벡터 인덱스를 최소 메모리, 거의 제로에 가까운 전처리 시간, 최고 수준의 정확도로 구축하고 쿼리할 수 있게 해준다.
구현 방향 (Next.js + Neon PostgreSQL + pgvector):
- 문서 업로드 → 임베딩 생성 → int8 양자화 후 저장
- 검색 시 full precision vs. 양자화 벡터 두 경로로 동시 검색
- 응답 속도, 메모리 사용량, 검색 결과 비교 대시보드 내장
- NextPads처럼 Vercel 즉시 배포
확장 포인트: AIGrape 리뉴얼 시 경량 임베딩 검색 백엔드로 발전 가능
5️⃣ “나의 LLM 운영 최적화” 진단 대시보드
“내 서비스에 몇 비트 양자화가 적합한가?”
핵심 아이디어: TurboQuant는 훈련이나 파인튜닝 없이 KV cache를 3비트까지 양자화하면서도 모델 정확도 손실 없이 원본 LLM보다 빠른 런타임을 달성한다.
구현 방향 (Streamlit 또는 React):
- 입력: 서비스 유형(챗봇/RAG/요약), 일일 요청 수, 평균 컨텍스트 길이, 허용 가능 정확도 손실 %
- 출력: 권장 양자화 비트폭 + 예상 메모리 절감 + 비용 절감 시나리오 3가지 (보수적/균형/공격적)
- Ollama로 로컬 모델 실행 시 적용 가이드까지 자동 생성
비즈니스 연결: NextPlatform 뉴스레터의 “이번 주 실험” 코너 또는 Goorm 중급 과정 프로젝트로 활용 가능

