2026.06.01 / 동준상.넥스트플랫폼
(AWS SAA, AWS AIF, GCP GenAI Leader)
이번 포스트에서는 단순한 챗봇 구현을 넘어, RAG 기반의 외부 지식 전달 방법과 이를 활용하는 실질적인 ‘지식 서비스’로서의 AI 에이전트 구축 방법에 대해 함께 알아봅니다.
1. 핵심 정리 (Executive Summary)

- AI 에이전트의 역할을 단순 API 호출 앱에서 외부 지식을 동적으로 활용하는 지식 서비스로 확장 목표
- 핵심 전략: RAG(검색 증강 생성, Retrieval-Augmented Generation) 기술을 활용하여 LLM의 한계를 극복하고, 실제 비즈니스 가치를 창출할 수 있는 리서치 도구 구축
- 주요 모델로 GPT(빠른 상호작용 및 도구 활용)와 Claude(긴 문서 분석 및 요약)를 전략적으로 병행 사용
- 데이터 수집, VectorDB 구축, 제품화 과정을 거쳐 MVP(최소 기능 제품)를 구현하는 단계별 로드맵 제시
2. RAG 아키텍처 및 모델 전략
2.1 RAG의 필요성과 구조
기존 GPT 모델의 한계를 극복하기 위해 외부 데이터를 검색하여 답변의 근거로 활용하는 RAG 구조를 채택합니다. 이는 AI가 고정된 학습 데이터에만 의존하지 않고, 최신 뉴스나 특정 도메인 지식을 실시간으로 참조할 수 있게 합니다.
2.2 모델별 역할 정의
목적에 따라 최적의 LLM을 선택하여 시스템의 효율성을 극대화합니다.
| 모델 | 주요 역할 및 강점 |
| GPT-4o-mini | 빠른 인터랙션, Tool Use(도구 활용), 실시간 UX 구현 |
| Claude | 긴 문서 요약, 심층 리서치, 고도화된 분석형 답변 |
| Gemini | 멀티모달 확장 가능성 제공 |
3. 데이터 수집 및 실습 아키텍처
3.1 권장 기술 스택
리서치 에이전트 구현을 위해 다음과 같은 표준 기술 스택이 권장됩니다.
- Frontend: React + Vite
- Backend: Node.js
- VectorDB: Chroma (입문 및 로컬 개발 최적화)
- Embedding: OpenAI Embedding
- Deployment: Vercel
3.2 주요 리서치 주제 및 데이터 소스
실제 활용 가능한 서비스 구축을 위해 NewsAPI 등을 활용한 데이터 확보가 필수적입니다.
- AI 뉴스 리서치: OpenAI, Anthropic, Google, NVIDIA 등 주요 기업 동향 추적
- 금융 뉴스 분석: 미국 증시, 금리, AI 반도체 시장 분석
- 유튜브 트렌드 리서치: AI 채널 분석, 제목 및 조회수 패턴 분석
4. VectorDB 구축: 검색 가능한 기억 저장소
데이터를 단순 저장하는 것이 아니라 검색 가능한 형태로 관리하기 위해 VectorDB를 활용합니다. 입문 단계에서는 확장성보다 직관성과 설치의 용이성을 고려하여 Chroma를 우선적으로 사용합니다.
4.1 구축 프로세스
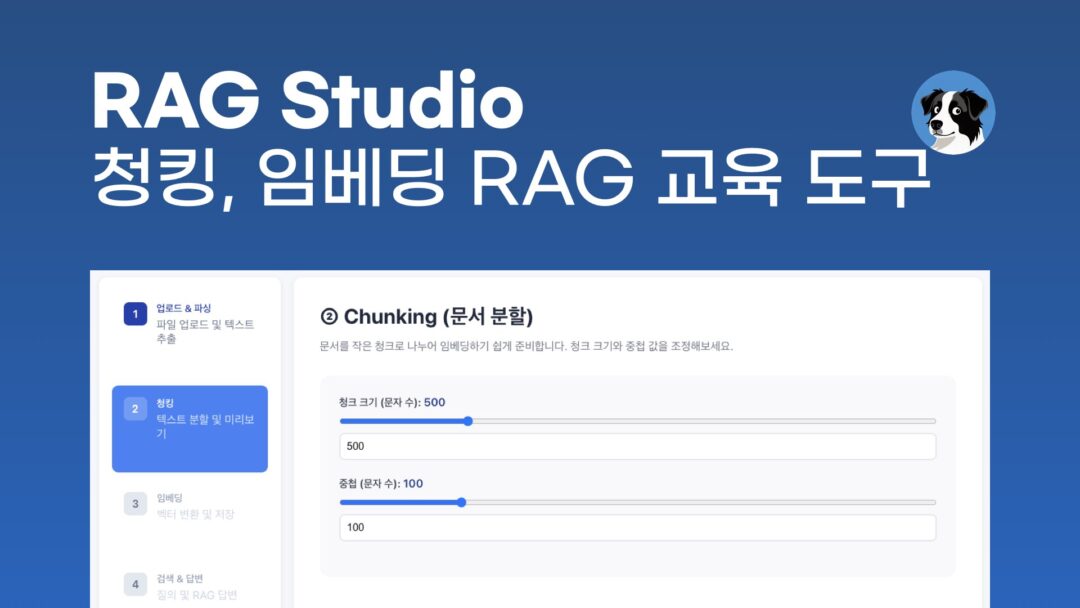
- Chunking: 수집된 텍스트 데이터를 처리하기 적절한 크기로 분할
- Embedding 생성: 텍스트를 벡터 데이터로 변환
- Chroma 저장: 검색 효율을 위해 VectorDB에 인덱싱
4.2 DB 비교 (Chroma vs FAISS)
| 항목 | Chroma | FAISS |
| 난이도 | 쉬움 (입문 추천) | 중간 |
| 로컬 개발 | 매우 우수 | 좋음 |
| 확장성 | 중간 | 높음 |
5. 제품화 전략 및 비즈니스 모델 (BM)
기술 데모 수준을 벗어나 실제 사용 가능한 서비스로 전환하기 위한 체크리스트와 비즈니스 확장 방향은 다음과 같습니다.
5.1 UX 및 UI 체크리스트
- 사용자 편의를 위한 검색창 및 추천 질문 기능
- 응답 대기 시간을 관리하는 로딩 상태 표시
- 정보의 가독성을 높이는 카드 UI 활용
5.2 단계별 구현 수준
- 초급: 뉴스 검색 및 단순 요약
- 중급: 투자 인사이트 생성 및 관련 기업 추천 기능
- 고급: 다중 에이전트(Multi-agent) 협업 및 자동 리포트 생성
5.3 비즈니스 모델 예시
- 구독형: 전문적인 프리미엄 리서치 서비스 제공
- 광고형: 뉴스 큐레이션 플랫폼 운영
- B2B: 기업 내부 문서 검색 및 분석 도구 제공
6. 현실적 제약 및 트레이드오프 (Trade-off)
시스템 구축 시 직면하게 되는 현실적인 문제들을 사전에 인지하고 대응해야 합니다.
- RAG 정확도: 검색된 정보가 항상 완벽할 수는 없음을 인지해야 합니다.
- 비용 관리: Embedding 생성 및 LLM(Claude/GPT) API 호출 비용이 실습 및 운영 시 빠르게 증가할 수 있습니다.
- 데이터 품질: Chunking의 품질이 최종 결과물의 품질에 결정적인 영향을 미칩니다.
결론: MVP 구현 성공 기준
리서치 에이전트 구축의 최종 목표는 기술적 완벽함보다 핵심 흐름의 완성에 있습니다. 성공적인 MVP 구현을 위해 다음의 4가지 기능을 핵심 범위로 설정합니다.
- 실시간 뉴스 데이터 수집
- VectorDB(Chroma) 저장 및 관리
- 사용자 질문에 대한 지능형 응답
- 뉴스 요약 정보 제공
안녕하세요! 바이브코딩 학습자들이 프로젝트의 전체 그림을 한눈에 파악하고 실습에 바로 적용할 수 있도록, 핵심 기술과 흐름 중심으로 정제한 마크다운 문서를 작성해 드립니다.
🚀 핸즈온 챌린지: AI 기반 블로그 포스팅 자동화 시스템 구현
다음은 “최신 트렌드 수집부터 블로그 업로드까지” 전 과정을 AI 에이전트가 대신 수행하는 자동화 시스템의 기술명세서입니다.
1. 프로젝트 목적 (The Goal)
- Problem: 매일 반복되는 자료 조사, SEO 분석, 글쓰기, 이미지 제작에 너무 많은 시간 소요.
- Solution: AI 에이전트가 트렌드를 읽고, 근거(RAG)를 바탕으로 글을 쓴 뒤 자동 발행하는 시스템 구축.
2. 시스템 아키텍처 (Structure)
학습자들이 이해하기 쉬운 5단계 데이터 흐름입니다.
- 데이터 수집: NewsAPI, YouTube, RSS를 통해 실시간 트렌드 확보.
- RAG 리서치: 수집한 정보를 VectorDB(Chroma)에 저장하고 필요할 때 검색.
- 에이전트 협업: 리서치 → 개요 작성 → 본문 작성 → SEO 최적화 순으로 분업.
- 미디어 생성: DALL·E 등을 활용해 글의 주제에 맞는 썸네일 자동 생성.
- 자동 배포: 완성된 마크다운(Markdown) 파일을 GitHub에 Push 하여 Vercel로 자동 배포.
3. 핵심 기능 상세 (Key Features)
🔵 Feature 1: RAG 기반 지능형 리서치
단순히 AI의 기억에 의존하는 것이 아니라, 실제 뉴스 데이터를 기반으로 글을 씁니다.
- 흐름: 문서 수집 → 쪼개기(Chunking) → 벡터화(Embedding) → DB 저장 → 검색.
- 추천 도구: 초보 단계에서는 설정이 간편한 Chroma 사용 권장.
🔵 Feature 2: Multi-Agent 글쓰기 프로세스
여러 명의 전문가(Agent)가 협업하는 구조로 높은 품질의 글을 만듭니다.
| 에이전트 | 역할 |
| Researcher | 뉴스 및 데이터 소스에서 관련 근거 수집 |
| Outline Agent | 수집된 정보를 바탕으로 목차 구성 |
| Writer Agent | 독자 친화적인 말투로 본문 작성 |
| SEO Agent | 클릭을 부르는 제목과 키워드 최적화 |
| Image Agent | 본문 내용에 어울리는 썸네일 프롬프트 생성 |
🔵 Feature 3: 원클릭 자동 배포
- Markdown 생성: AI가 최종본을 마크다운 형식으로 출력.
- GitHub 연동: 코드와 콘텐츠를 자동으로 업데이트.
- Vercel 배포: 수정한 내용이 실시간으로 블로그 웹사이트에 반영.
4. 추천 기술 스택 (Tech Stack)
실습의 편의성과 확장성을 고려한 조합입니다.
- Frontend:
React+Vite+Tailwind CSS - Backend:
Node.js(Express) - AI 프레임워크:
LangGraph(에이전트 워크플로우 제어) - LLM API:
GPT-4o-mini(가성비 최고),Claude 3.5 Sonnet(글쓰기 품질) - Database:
Chroma(Vector),Supabase(User Data)
5. 실습 핵심 단계 (Hands-on Steps)
MVP(최소 기능 제품) 구현 범위입니다.
- [1단계] 뉴스 및 유튜브 API를 연동하여 실시간 데이터 가져오기.
- [2단계] OpenAI Embedding을 이용해 데이터를 VectorDB에 저장하기.
- [3단계] 에이전트 워크플로우를 설계하여 블로그 초안(Markdown) 생성하기.
- [4단계] 생성된 파일을 GitHub API를 통해 자동으로 저장소에 올리기.
💡 학습자 가이드 (Tips)
- 검수 필수: AI가 생성한 글에는 환각(Hallucination)이 있을 수 있으므로 최종 발행 전 확인 단계가 필요합니다.
- API 비용:
GPT-4o-mini모델을 사용하면 매우 저렴한 비용으로 수천 건의 포스팅 테스트가 가능합니다. - 확장성: 익숙해지면 X(트위터)나 인스타그램용 짧은 요약본 생성 기능을 추가해 보세요!
이 명세서를 바탕으로 멋진 나만의 뉴스 에이전트를 구축해 보세요! 🚀