Quantization Algorithm for AI Innovation: TurboQuant vs. EDEN
핵심 요약 (Executive Summary)
이번 포스트에서는 AI 반도체와 AI 시스템을 위한 혁신적인 정보 처리 기법으로 주목받고 있는 양자화 알고리즘 중 하나인 EDEN과 최근 구글이 발표한 TurboQuant의 기술 기반에 대해 살펴봅니다.
주요 시사점:
- 성능 우위: EDEN-biased는 모든 테스트 차원과 비트 폭에서 TurboQuant-mse보다 낮은 평균 제곱 오차(MSE)를 기록
- 비트 효율성: 비편향(Unbiased) 압축 기반의 EDEN-unbiased는 TurboQuant-prod보다 효율적이며, 1비트 더 적은 예산으로도 더 높은 정확도를 제공
- 구조적 결함 지적: TurboQuant-mse는 EDEN의 스케일링이 생략된 퇴행적 사례(Degenerate case)로 평가, TurboQuant-prod의 비트 분할 전략은 단일 패스 방식인 EDEN보다 분산 수준이 높음
- 실무적 가치: EDEN은 분산 학습, KV 캐시 압축, 임베딩 검색 등 현대 대규모 언어 모델(LLM) 인프라의 핵심 영역에서 이미 성능 검증, 주요 프레임워크(PyTorch, TensorFlow 등)에서 즉시 사용 가능
- 양자화 알고리즘의 핵심적인 차별점: ‘최적 스케일 파라미터(S)’의 유무, EDEN은 이를 분석적으로 도출하여 데이터 손실을 최소화 가능
1. EDEN 양자화 알고리즘의 구조 및 메커니즘
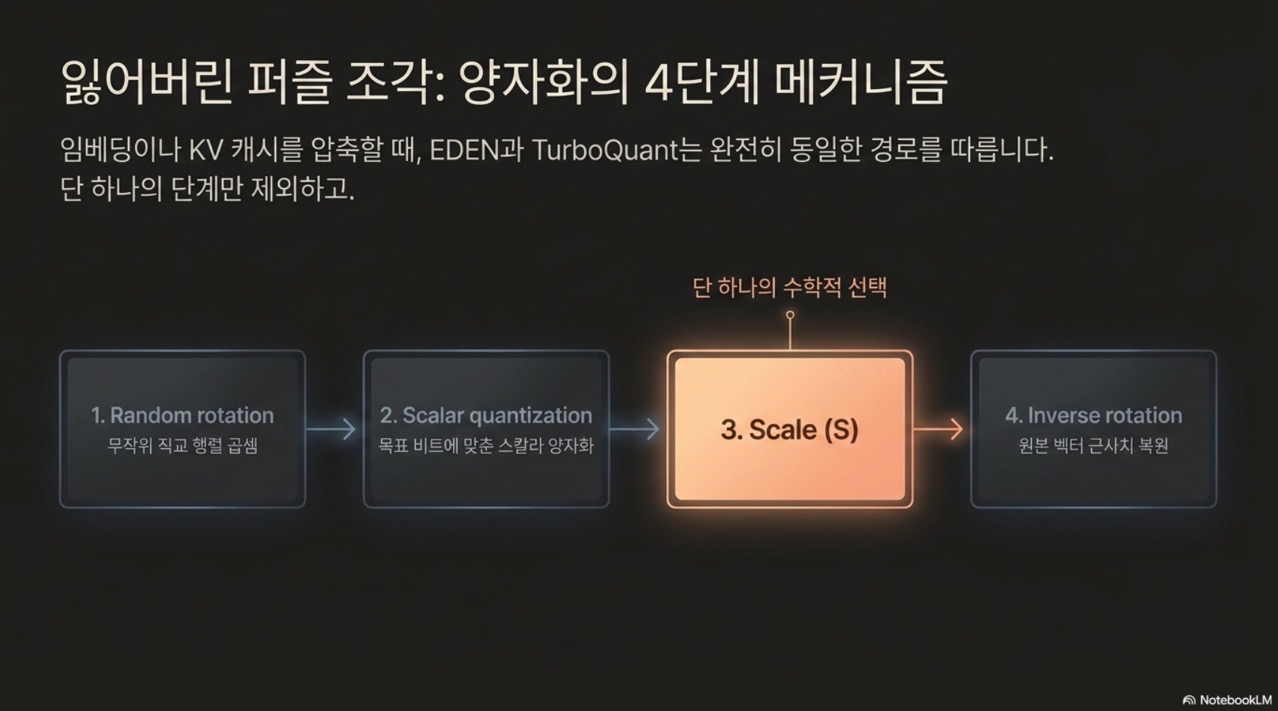
EDEN은 벡터(그래디언트 업데이트, 임베딩, KV 캐시 항목 등)를 좌표당 몇 비트로 압축하기 위해 4단계 프로세스를 수행한다.
1.1 양자화 4단계
- 무작위 회전 (Random Rotation): 무작위 직교 행렬(\Pi)을 곱한다. 이를 통해 좌표는 동일한 분포(대규모 차원의 경우 가우스 분포에 근접)를 갖게 된다.
- 스칼라 양자화 (Scalar Quantization): 회전된 각 좌표를 Lloyd-Max 코드북을 사용하여 2^b 수준 중 하나로 반올림한다.
- 스케일링 (Scale): 분석적으로 도출된 스케일 인자 S를 곱한다.
- 역회전 (Inverse Rotation): 역행렬(\Pi^\top)을 적용하여 원래 벡터의 근사치(\hat{x})를 복원한다.
1.2 스케일 파라미터(S)의 역할
EDEN의 핵심 혁신은 무작위 회전 후 좌표가 알려진 분포를 따른다는 점을 활용하여 **분석적 폐쇄형 스케일(Closed-form scale)**을 적용한다는 것이다.
- EDEN-biased: 재구성 MSE를 최소화하는 S 값을 설정한다.
- EDEN-unbiased: 출력의 기댓값이 원본과 일치하도록(E[\hat{x}] = x) S를 선택한다.
2. TurboQuant와의 기술적 비교 분석
EDEN과 TurboQuant는 구조적으로 유사하지만, 스케일링 처리 방식에서 결정적인 성능 차이가 발생한다.
2.1 EDEN-biased vs. TurboQuant-mse
TurboQuant-mse는 MSE 최소화를 목표로 함에도 불구하고 최적 스케일링 단계를 생략한다(즉, S=1로 고정). 이는 EDEN의 특수한 하위 사례이자 성능이 낮은 버전으로 간주된다.
| 비교 항목 | EDEN-biased | TurboQuant-mse |
| 스케일링 (S) | 분석적 최적화 값 적용 | S=1 고정 |
| 성능 (MSE) | 모든 차원에서 더 낮음 | 상대적으로 높음 |
| 차원별 차이 | 실무적 차원(128~1024)에서 우세 | 대규모 차원에서만 EDEN에 수렴 |
특히 128차원에서 4비트를 사용하는 실무 환경의 경우, EDEN-biased는 TurboQuant-mse 대비 MSE를 2.25% 감소시킨다.
2.2 EDEN-unbiased vs. TurboQuant-prod
분산 학습이나 근사 어텐션(Approximate Attention) 등 평균화 작업이 중요한 환경에서는 편향되지 않은(Unbiased) 추정이 필수적이다.
- TurboQuant-prod의 방식: 비트 예산을 분할하여 (b-1) 비트는 편향된 TurboQuant-mse에 사용하고, 나머지 1비트는 잔차 수정을 위한 QJL(Quantized Johnson-Lindenstrauss)에 할당한다.
- EDEN-unbiased의 방식: 전체 비트 예산을 단일 스케일 최적화 양자화기에 집중 투자한다.
비교 결과:
- 분산 차이: 대규모 차원에서 EDEN의 1비트 vNMSE는 약 0.57로 수렴하는 반면, QJL은 약 1.57로 수렴하여 EDEN이 약 2.75배 낮은 분산을 보인다.
- 비트 효율성: EDEN-unbiased의 b 비트 성능이 TurboQuant-prod의 (b+1) 비트 성능보다 우수한 경우가 빈번하다. 즉, EDEN으로 교체하는 것만으로도 정확도 손실 없이 좌표당 1비트를 절약할 수 있다.
3. 벤치마크 및 실증적 증거
표준 ANN(Approximate Nearest Neighbor) 벤치마크 데이터셋인 Stanford의 GloVe와 Qdrant의 OpenAI3 임베딩을 통한 평가 결과는 다음과 같다.
- 정확도: EDEN-biased는 TurboQuant-mse보다 일관되게 낮은 MSE를 달성했다.
- 검색 성능: 2비트 및 4비트 설정에서 근사 최근접 이웃(Nearest-Neighbor) 리콜(Recall) 값이 EDEN에서 더 높게 나타났다.
- 내적 오차: EDEN-unbiased는 TurboQuant-prod보다 현저히 낮은 내적 오차를 기록했다.
4. 발전 계보 및 생태계 적용 현황
EDEN은 2021년 DRIVE 알고리즘에서 시작되어 다양한 최신 AI 기술의 기반이 되었다.
- 알고리즘 진화:
- DRIVE (2021): 1비트 분산 평균 추정.
- EDEN (2022): 임의의 비트 폭으로 일반화.
- HIGGS (2025): 데이터 프리(Data-free) LLM 가중치 압축으로 확장.
- AQUA-KV (2025): 적응형 KV 캐시 양자화에 적용.
- Quartet II (2026): NVFP4 LLM 학습을 위한 MS-EDEN 변형.
- 소프트웨어 구현:
- 프레임워크: PyTorch, TensorFlow 공식 지원.
- 엔터프라이즈/오픈소스: Intel OpenFL, Google FedJax, TensorFlow Federated 등에 통합.
- 실제 적용: vLLM의 인기 있는 구현체들이 사실상 EDEN의 스케일링 방식(두 EDEN 스케일의 기하 평균)을 활용하여 키(Key) 양자화를 수행하고 있음이 확인되었다.
결론
- 최신 기술로 주목받은 TurboQuant는 실제로는 과거에 이미 확립된 EDEN 알고리즘의 최적화된 스케일링을 누락하거나 비효율적인 비트 분할 전략을 사용
- 모델 가중치 압축, KV 캐시 최적화, 임베딩 검색 등 정확도와 효율성이 동시에 요구되는 영역에서 EDEN 계열의 알고리즘을 사용하는 것이 기술적으로 더 좋은 선택일 수 있음

