

2026.02.05 / JUN.NXP
이번 포스트에서는 Anthropic의 최신 AI 모델인 Claude Opus 4.6의 주요 기능, 성능 지표, 안전성 프로필 및 제품 업데이트 내용을 종합적으로 분석합니다.
핵심 요약 (Executive Summary)
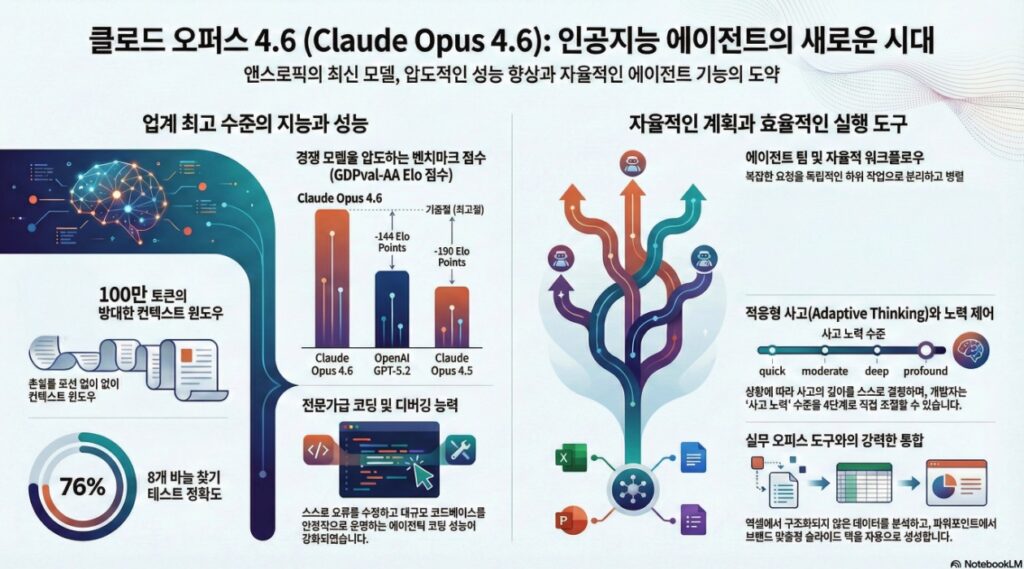
Claude Opus 4.6은 Anthropic의 가장 지능적인 모델을 업그레이드한 버전으로, 특히 코딩 역량, 에이전트 작업 수행, 복잡한 추론 능력에서 비약적인 발전을 이루었습니다. 주요 혁신 사항으로는 100만 토큰 컨텍스트 윈도우(베타) 도입, 적응형 사고(Adaptive Thinking) 기능, 그리고 업계 최고 수준의 에이전트 기획(Agentic Planning) 능력이 꼽힙니다.
이 모델은 금융, 법률, 코딩 등 전문적인 도메인에서 경쟁 모델인 OpenAI의 GPT-5.2 및 이전 모델인 Opus 4.5를 능가하는 성능을 보여주었으며, 안전성 측면에서도 업계 최고 수준의 정렬(Alignment) 상태를 유지하고 있습니다. 개발자와 기업 사용자 모두에게 더 높은 자율성과 정밀한 제어 기능을 제공하도록 설계되었습니다.
Claude Opus 4.6 핵심 기능 목록
| 벤치마크 또는 기능 | 성능 지표/특징 | 이전 모델 대비 개선점 (추론) | 적용 분야 |
| GDPval-AA (경제적 가치 지식 작업) | OpenAI GPT-5.2 대비 약 144 Elo 포인트 우위 | Opus 4.5 대비 190 포인트 향상되어 전문 지식 작업 능력이 대폭 강화됨 | 금융, 법률 및 기타 전문 도메인 업무 |
| 복합 추론 (Humanity’s Last Exam) | 모든 프런티어 모델 중 선두 기록 | 복합적인 다학제적 추론 및 문제 해결 능력의 정점 도달 | 전문가 수준의 복합 추론 업무 |
| 코딩 능력 (Terminal-Bench 2.0) | 에이전틱 코딩 평가에서 업계 최고 점수 획득 | 더욱 세심한 계획 수립 및 대규모 코드베이스에서의 안정적 작동 능력 향상 | 소프트웨어 엔지니어링, 코드 리뷰 및 디버깅 |
| 컨텍스트 윈도우 (Context Window) | 베타 버전에서 1M(1,000,000) 토큰 지원 | Opus급 모델 최초의 1M 토큰 지원으로 방대한 정보 처리 가능 | 대규모 코드베이스 분석 및 긴 문서 연구 |
| Long-context Retrieval (MRCR v2 8-needle 1M) | 76% 점수 기록 (Sonnet 4.5의 18.5% 대비 월등) | 이전 모델이 놓치던 묻혀 있는 세부 정보를 찾아내는 ‘컨텍스트 부패’ 방지 능력 개선 | 대용량 문서 세트 내 정보 검색 및 요약 |
| BigLaw Bench (법률 벤치마크) | 90.2% 기록 (역대 Claude 모델 중 최고점) | 법률적 추론 능력에서 가시적인 성능 점프 달성 | 법률 분석 및 서류 검토 |
| 생명과학 지식 테스트 | 컴퓨팅/구조 생물학, 유기 화학 등에서 이전 대비 약 2배 성능 향상 | 전문 과학 도메인 지식의 정확도 및 이해도 2배 개선 | 생명과학 연구 및 학술 분석 |
| 에이전틱 기능 (Adaptive Thinking & Effort Control) | 상황에 따른 사고 깊이 자율 결정 및 4단계 노력 수준 제어 | 단순 이진 선택에서 벗어나 지능, 속도, 비용 간의 유연한 조절 가능 | 자율 워크플로우 개발 및 API 최적화 |
| 오피스 도구 통합 (Excel & PowerPoint) | 비구조화 데이터 구조화 및 브랜드 가이드 준수 슬라이드 생성 | 수동 조작 최소화 및 한 번의 패스로 다단계 변경 수행 가능 | 재무 분석, 프레젠테이션 제작 등 일상 사무 업무 |
| 안전성 및 정렬 (Automated Behavioral Audit) | 업계 최저 수준의 과잉 거절(Over-refusals) 및 높은 정렬 수준 유지 | 지능 향상에도 불구하고 Opus 4.5 수준의 최고 안전 프로필 유지 및 사용자 경험 개선 | 기업용 AI 시스템 및 안전이 중시되는 인터페이스 |
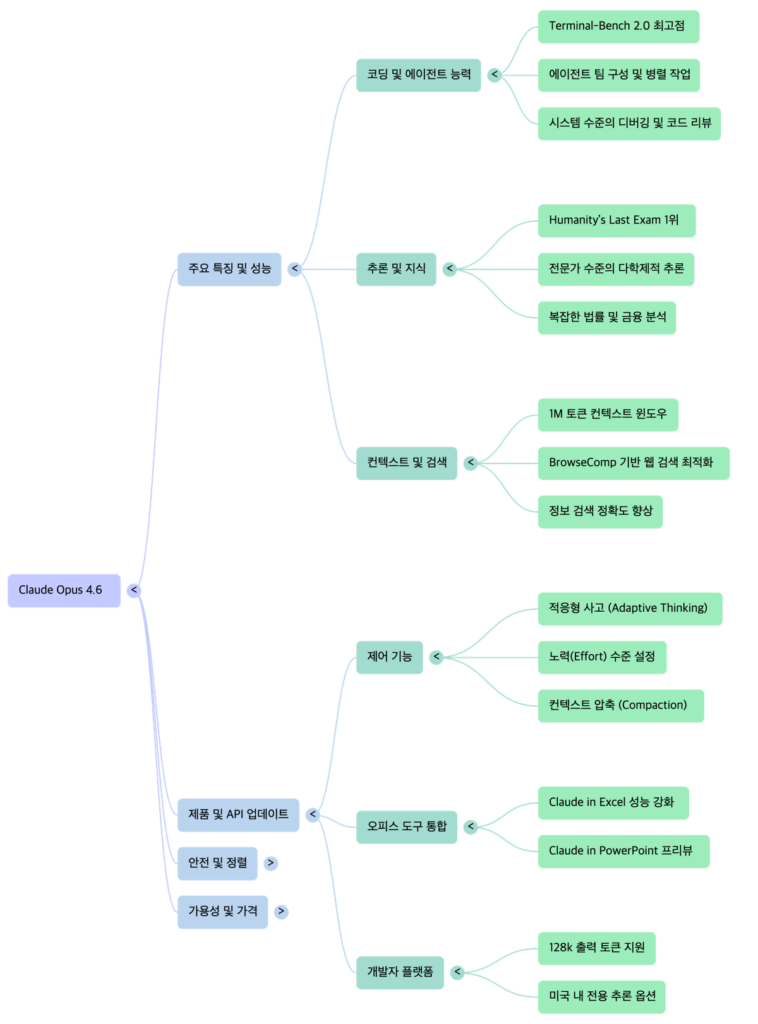
1. 주요 기술적 역량 및 특징
1.1 에이전트 중심 코딩 및 시스템 작업
Opus 4.6은 이전 모델보다 더욱 세밀한 계획 수립과 장기적인 에이전트 작업 수행 능력을 갖추고 있습니다.
- 대규모 코드베이스 운용: 더 큰 규모의 코드베이스에서 안정적으로 작동하며, 코드 리뷰 및 디버깅 능력이 향상되어 스스로의 오류를 더 잘 잡아냅니다.
- 자율적 문제 해결: 모호한 문제에 대해 더 나은 판단력을 발휘하며, 수동적인 가이드 없이도 복잡한 요청을 구체적인 단계로 나누어 실행합니다.
- Claude Code 내 에이전트 팀: 사용자는 여러 에이전트를 팀으로 구성하여 병렬로 작업을 수행하고 자율적으로 협업하게 할 수 있습니다.
1.2 장기 문맥(Long-context) 처리 및 검색 능력
- 1M 토큰 컨텍스트: Opus급 모델 최초로 100만 토큰 컨텍스트 윈도우를 지원하여 방대한 양의 정보를 한 번에 처리할 수 있습니다.
- 문맥 부패(Context Rot) 방지: 대화가 길어질수록 성능이 저하되는 현상을 획기적으로 개선했습니다. ‘바늘찾기(Needle-in-a-haystack)’ 테스트(MRCR v2 1M 변형)에서 76%의 점수를 기록하며 경쟁 모델(Sonnet 4.5, 18.5%)을 압도했습니다.
- 문맥 압축(Context Compaction): 대화 내용이 한계에 도달하면 자동으로 이전 문맥을 요약 및 교체하여 끊김 없는 작업 수행을 지원합니다.
2. Claude Opus 4.6 vs. OpenAI GPT-5.2 vs. Google Gemini 3 Pro 성능 비교
Claude Opus 4.6과 경쟁 모델인 OpenAI의 GPT-5.2, Google의 Gemini 3 Pro 등을 비교 분석한 자료에 따르면 Opus 4.6은 여러 주요 벤치마크에서 경쟁 모델들을 앞서는 결과를 보여주었습니다. 특히 경제적 가치 평가(GDPval-AA)와 복합 추론 능력에서 두드러진 성과를 기록했습니다.
Claude Opus 4.6 vs. GPT-5.2 및 최신 모델 비교
| 평가 항목 (Benchmark) | Claude Opus 4.6 성능 | 경쟁 모델 (GPT-5.2, Gemini 3 Pro 등) 비교 현황 |
|---|---|---|
| 경제적 지식 노동 가치 (GDPval-AA) | 업계 1위이전 모델(Opus 4.5) 대비 +190 Elo 포인트 상승 | GPT-5.2 대비 +144 Elo 포인트 우위GPT-5.2와 비교 시 약 70%의 승률 기록 |
| 복합 다학제 추론 (Humanity’s Last Exam) | 모든 프런티어 모델 중 선두 (Leads all other frontier models) | GPT-5.2 및 Gemini 3 Pro를 포함한 경쟁 모델보다 우수한 성과 기록 |
| 에이전트 코딩 (Terminal-Bench 2.0) | 최고 점수 (Highest Score) | 타사 최신 모델들보다 높은 점수 획득 |
| 정보 검색 및 위치 파악 (BrowseComp) | 타 모델 대비 우수 (Better than any other model) | 온라인상의 찾기 힘든 정보를 찾는 능력에서 경쟁 모델 압도 |
| 장문 맥락 유지 (Context & Retrieval) | 76% 점수 (1M 토큰, Needle-in-a-haystack 테스트) | 경쟁 모델들이 겪는 ‘컨텍스트 부패(Context Rot)’ 문제를 획기적으로 개선 (참고: 자사 Sonnet 4.5는 18.5% 기록) |
| 안전성 (Safety Profile) | 업계 프런티어 모델 중 최고 수준의 안전성 및 정렬(Alignment) 유지 | 타사 모델과 동등하거나 그 이상의 안전성 프로필 확보 |
주요 비교 포인트 및 기술적 우위
1. 경제적 가치 창출 능력 (GDPval-AA) Opus 4.6은 금융, 법률 등 경제적 가치가 높은 지식 노동 업무를 평가하는 GDPval-AA 지표에서 GPT-5.2보다 약 144 Elo 포인트 더 높은 점수를 기록했습니다. 이는 두 모델이 대결했을 때 Opus 4.6이 이길 확률이 약 70%에 달한다는 것을 의미합니다. 이는 단순한 문제 풀이 능력을 넘어 실무에서의 효용성이 경쟁사 모델보다 뛰어남을 시사합니다.
2. 컨텍스트 처리 및 유지 능력 (Context Handling) 많은 AI 모델들이 대화가 길어질수록 성능이 저하되는 ‘컨텍스트 부패(Context Rot)’를 겪습니다. 하지만 Opus 4.6은 100만 토큰(1M token) 컨텍스트 윈도우 내에서 정보를 찾아내는 테스트에서 76%의 높은 점수를 기록하며, 방대한 데이터를 처리하는 능력에서 질적인 도약을 이루었습니다.
3. 기능적 유연성 및 제어 (Control & Flexibility) 경쟁 모델들과의 차별점 중 하나는 개발자와 사용자가 모델의 리소스 사용을 제어할 수 있는 기능입니다.
- 적응형 사고(Adaptive Thinking): 모델이 문제의 난이도에 따라 깊게 생각할지 여부를 스스로 결정하거나 사용자가 설정할 수 있습니다.
- 컨텍스트 압축(Context Compaction): 긴 작업을 수행할 때 이전 내용을 자동으로 요약하여 토큰 제한에 걸리지 않고 작업을 지속할 수 있게 해줍니다.
4. 벤치마크 범위 제공된 자료의 각주에 따르면, 비교 대상이 된 경쟁 모델들은 해당 시점(차트 및 테이블 기준)에서 보고된 GPT-5.2와 Gemini 3 Pro의 최고 버전들이었습니다. Opus 4.6은 코딩, 사이버 보안, 생명 과학 등 다양한 전문 분야 벤치마크에서도 이들 모델보다 뛰어난 성과를 입증했습니다.
최신 LLM FM 버전 요약: Claude Opus 4.6은 GPT-5.2 및 Gemini 3 Pro와 같은 최신 경쟁 모델들과 비교했을 때, 특히 복잡한 에이전트 작업, 코딩, 그리고 긴 문맥을 다루는 업무에서 명확한 성능 우위를 점하고 있습니다.
3. 안전성 및 윤리적 정렬
Opus 4.6은 지능의 향상이 안전성의 저하를 의미하지 않음을 입증했습니다.
- 정렬 상태: 자동화된 행동 감사 결과 기만, 아첨, 오용 협조 등 부적절한 행동 발생률이 매우 낮으며, 이전 모델인 Opus 4.5와 대등하거나 그 이상의 안전성을 확보했습니다.
- 과잉 거부 감소: 무해한 요청에 대해 답변을 거부하는 ‘과잉 거부(Over-refusals)’ 비율이 최근 Claude 모델 중 가장 낮습니다.
- 사이버 보안 강화: 모델의 향상된 사이버 보안 능력이 악용되는 것을 방지하기 위해 6가지 새로운 보안 프로브를 개발했습니다. 또한, 오픈소스 소프트웨어의 취약점을 찾고 패치하는 등 방어적 활용을 가속화하고 있습니다.
4. 제품 및 API 업데이트

4.1 개발자 플랫폼 기능
- 적응형 사고(Adaptive Thinking): 모델이 문맥적 단서를 파악하여 심층 추론이 필요한 시점을 스스로 결정합니다.
- 노력(Effort) 제어: 개발자는
low,medium,high(기본값),max등 4단계의 노력 수준을 설정하여 지능, 속도, 비용 간의 균형을 직접 조절할 수 있습니다. - 출력 토큰 확대: 최대 128k 토큰의 출력을 지원하여 대규모 출력 작업을 한 번에 완료할 수 있습니다.
4.2 업무 도구 통합
- Excel 및 PowerPoint: Excel에서의 데이터 구조화 및 처리 능력이 대폭 향상되었으며, PowerPoint 연구 프레뷰를 통해 Excel 데이터를 시각적인 발표 자료로 자동 변환하는 기능을 지원합니다. 브랜드 레이아웃, 글꼴 및 슬라이드 마스터를 준수합니다.
5. 주요 파트너 및 초기 사용자 피드백
초기 액세스 파트너들은 Opus 4.6에 대해 다음과 같이 평가했습니다.
“Opus 4.6은 복잡한 요청을 구체적인 단계로 나누어 실행하고 세련된 결과물을 만들어내는 능력이 탁월하다. Notion 사용자들에게는 단순한 도구가 아닌 역량 있는 협업자로 느껴진다.”
“수백만 줄에 달하는 코드베이스 마이그레이션을 선임 엔지니어처럼 처리했다. 미리 계획을 세우고 학습하며 전략을 수정하여 작업 시간을 절반으로 단축시켰다.”
“멀티 소스 분석(법률, 금융, 기술 콘텐츠)에서 탁월하다. 기술 도메인에서 거의 완벽한 점수를 기록하며 기준 대비 10%의 성능 향상을 보였다.”
“단 한 번의 시도(One-shot)로 완전히 작동하는 물리 엔진을 생성했다. 대규모 멀티 스코프 작업을 한 번에 처리하는 능력이 놀랍다.”
결론
Claude Opus 4.6은 자율적인 에이전트로서의 기능과 장기 문맥 처리 능력에서 질적인 도약을 이뤘으며, 특히 ‘적응형 사고’와 ‘노력 제어’ 기능을 통해 사용자가 필요에 따라 모델의 추론 깊이를 조절할 수 있게 함으로써, 효율성과 성능을 동시에 잡은 도구로 평가됩니다.
이번 Anthropic의 최신 Claude 모델이 복잡한 추론, 대규모 코딩, 그리고 전문적인 지식 업무를 수행하는 모든 분야에서 강력한 기준점이 될 수 있을지 살펴봐야겠습니다.
참고자료 / 다운로드
Claude Opus 4.6 모델 사양 및 주요 벤치마크 성능 비교표 (다운로드)
https://docs.google.com/spreadsheets/d/1C04_ZDGGP9eCboh4phUYHtbJ967Al89LCi3MO6rfWjI/edit?usp=sharing
Claude Opus 4.6 모델 사양 및 주요 벤치마크 성능 분석 슬라이드 (PDF 다운로드)
https://drive.google.com/file/d/12nUkzIsRrwv5AkhedRdjBqzj0t1EKdXD/view?usp=sharing

