25.08.24 / JUN
AX 강의 중 거의 매번 받는 질문 중 하나는 ‘데이터 보안이 유지되는 상태에서 챗GPT를 사용하는 방법이 있어요?’라는 질문입니다. 20달러 또는 200달러의 구독료를 절감할 수 있거나 아예 무료로 사용할 수 있는 챗GPT 모델에 대한 질문도 자주 받습니다. 정보 보안과 구독 비용 문제를 동시에 해결할 수 있는 해법 중 하나가 바로 나의 컴퓨팅 환경에 설치해서 쓰는 로컬 LLM 방식입니다.
보안 네트워크 내에서 안전하게 실행할 수 있는 로컬 LLM으로는 오픈AI가 제공하는 GPT 경량화 모델인 gpt‑oss, 구글 딥마인드에서 제공하는 Gemma, 중국 알리바바가 제공하는 Qwen, 그리고 또 다른 중국 로컬 LLM 모델인 DeepSeek가 있습니다. 이번 포스트에서는 이들 폐쇄망에서 실행 가능한 로컬 LLM에 대해 알아봅니다.
모델별 개요 및 특징
gpt-oss (OpenAI)
- 개요: OpenAI가 2025년 8월 발표한 gpt‑oss‑20b 및 gpt‑oss‑120b 모델은 Apache 2.0 라이선스 하에 공개된 첫 오픈 웨이트 모델
- 특징:
- 로컬 실행 가능: gpt‑oss‑20b는 16 GB 메모리로도 작동 가능, gpt‑oss‑120b는 80 GB GPU 한 장에서 실행 가능
- MoE 아키텍처, Mixed-sparse attention, chain‑of‑thought reasoning 지원, 최대 128k 토큰 컨텍스트 길이 제공
- 오픈 웨이트이면서 상업적 사용 및 fine‑tuning 가능
Qwen (Alibaba Cloud)
- 개요: Alibaba Cloud에서 개발한 LLM 시리즈. dense 및 sparse, 텍스트/멀티모달 모델 포함. 일부 모델은 Apache 2.0 라이선스로 공개됨
- 특징:
- 다양한 버전 출시 (Qwen2.5‑Max, Qwen3 등), multimodal 입력(텍스트·이미지·비디오·오디오) 지원 (예: Qwen2.5‑Omni‑7B)
- Qwen 3 모델은 최대 235B 파라미터(22B 활성) 및 128K 컨텍스트 길이 제공
- 벤치마크 성능: Qwen‑72B는 LLaMA‑2‑70B를 뛰어넘고 GPT‑3.5보다 7/10 과제에서 우수함
Gemma (Google DeepMind)
- 개요: Google DeepMind의 오픈 웨이트 LLM 계열. Gemini 기술 기반이며, Gemma, Gemma 2, Gemma 3 등 세대별 출시됨
- 특징:
- 크기와 기능 다양: Gemma 3는 1B / 4B / 12B / 27B 파라미터, 140개 이상 언어 및 멀티모달 지원
- Gemma 3 270M 모델은 초경량(INT4 양자화), 전력 효율 우수, instruction-following에 특화
- 오픈 웨이트로 fine-tuning 가능, Vertex AI 등과 연동 가능
DeepSeek (DeepSeek AI, 중국)
- 개요: DeepSeek LLM은 7B 및 67B 모델로 공개된 오픈 웨이트 LLM. 2조 토큰 데이터로 학습됨
- 특징:
- 67B model은 LLaMA2 70B보다 reasoning, 코딩, 수학, 중국어 이해 등에서 우수한 성능
- DeepSeek-R1은 MoE, chain‑of‑thought, RL 등 혼합 구조: 의료·수학 분야 USMLE, AIME 등 경쟁력 있는 성능 보여줌
- Open source이며 비용 효율과 투명성을 목표로 함
- 단점: 편향, 오정보, 안전성 문제 발생 가능성 있음
모델 비교: 개요·성능·장단점
| 모델 | 개요 | 성능 및 특징 | 주요 장점 | 한계/단점 |
|---|---|---|---|---|
| gpt-oss-20b / 120b | OpenAI 오픈 웨이트 LLM (Apache 2.0) | o3-mini / o4-mini 수준, chain-of-thought, MoE, 128k 컨텍스트 | 상업용 사용 가능, 로컬 실행, 높은 reasoning 성능 | 120b는 고사양 필요 (80GB GPU) |
| Qwen 시리즈 | Alibaba LLM + multimodal (Apache 일부) | LLaMA2-70B 초월, multimodal, 대규모 파라미터 | 멀티모달, 다양한 버전, 에이전트 지원 | 일부 최신 모델은 비공개, open source 범위 제한 |
| Gemma (1B~27B, 270M 등) | Google DeepMind 오픈 웨이트 LLM | instruction-follow, 경량, 멀티모달, 다국어 | 전력 효율 우수, 가벼움, fine-tuning 용이 | 대형 벤치마크 성능은 제한적 정보 |
| DeepSeek (7B/67B, R1) | 중국 DeepSeek 오픈 모델 (MIT 라이선스) | reasoning, 의료·수학 분야 우수, 코딩·중문 성능 강함 | 비용 효율, 混構アーキ텍처Mix, 투명성 | 편향·오정보 위험, 안전성 과제 존재 |
요약 및 활용 추천
- 로컬 실행 및 강력 추론 성능을 원하는 경우: gpt-oss-20b/120b가 훌륭한 선택이며, 특히 오프라인, 민감 데이터 작업에 적합합니다.
- 멀티모달 및 다양한 입력/출력 모델을 원할 때: Qwen 시리즈가 텍스트, 이미지, 비디오, 오디오까지 폭넓게 지원하며, agentic 기능도 강점입니다.
- 저사양 환경 혹은 빠른 fine-tuning이 필요할 때: Gemma 3 270M은 배터리 효율성과 낮은 연산 요구가 강점입니다.
- 의료, 수학, 구조화된 문제 해결 능력을 강조할 경우: DeepSeek-R1이 해당 영역에서 특히 강력한 성능을 보입니다.
“오픈소스 LLM, 추론 시 토큰 사용량 최대 10배↑… 비용 절감 효과 없다”
참고 | 오픈 로컬 LLM, 추론 시 토큰 사용량 최대 10배 높아… 비용 절감 효과 크지 않음
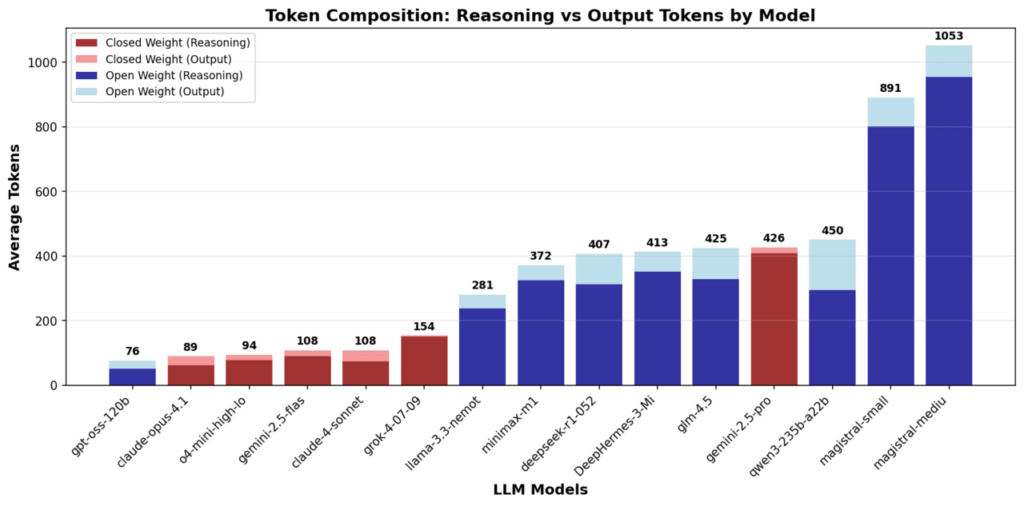
- 누스 리서치 연구 결과: 오픈소스(open-weight) LLM이 폐쇄형 모델보다 1.5~10배 더 많은 토큰을 사용.
- 토큰 효율성 문제: 단순 지식 질문조차 불필요한 사고 과정을 거쳐 수천 개 토큰을 소모.
- 실험 범위: 19개 모델을 대상으로 지식 질의·수학·논리 퍼즐 수행 비교.
- 비교 성능: OpenAI ‘o4-미니’, gpt-oss는 최소 3배 효율적 토큰 사용, 반면 Qwen·DeepSeek 등은 버전이 오를수록 비효율 심화.
- 원인 분석: 정확도 향상에 치중하며 Chain-of-Thought(COT) 활용, 단순 작업에도 과도한 연산 발생.
- 기업 영향: 토큰 단가보다 **총 연산량(효율성)**이 실제 비용을 좌우, 폐쇄형 모델이 오히려 비용 경쟁력 가질 수 있음.
기업 및 공공기관을 위한 로컬 LLM 활용
1. 로컬 LLM 개요
- 정의: 클라우드 서버가 아닌 사내 PC, 서버, 워크스테이션에서 직접 실행 가능한 AI 모델
- 주요 모델: gpt-oss(OpenAI), Gemma(Google), Qwen(Alibaba), DeepSeek(중국)
- 실행 방식: GPU·CPU 기반, Ollama·LM Studio·Transformers 활용
2. 왜 필요한가? (필요성)
- 데이터 보안: 민감한 기밀 데이터(국방·금융·행정 등) 외부 유출 방지
- 비용 절감: 대규모 API 호출 대비, 장기적으로 운영비 절약
- 속도/접근성: 인터넷 연결 없이도 내부 환경에서 빠르게 응답
- 커스터마이징: 사내 데이터로 fine-tuning 가능
3. 타겟 고객
- 기업: 금융사, 제조사, 유통사 – 사내 데이터 활용 AI 분석
- 공공기관: 국방, 행정, 교육, 보건 – 기밀성/규제 준수 요구
- 연구기관: AI 연구, 자연어 처리, 데이터 과학
4. 장점
- 프라이버시 보장 (데이터 외부 전송 없음)
- 맞춤형 모델 학습 가능 (특정 도메인 언어·문서)
- 오프라인 환경에서도 동작 가능
- 장기적 비용 절감
5. 단점
- 고성능 하드웨어 요구 (GPU·RAM)
- 운영·유지보수 복잡 (업데이트, 최적화 필요)
- 모델 크기·성능 한계 (초대형 클라우드 모델 대비)
- 보안 설정 미흡 시 내부 유출 가능
6. 정보보안을 위한 주의 사항
- 내부망 전용 운영: 인터넷 차단 환경에서 활용 권장
- 접근 제어: 모델 서버 접근 권한 최소화
- 로그 관리: 입력·출력 데이터 기록 및 보안 검토
- 업데이트 검증: 공식 저장소(Hugging Face, GitHub) 통해 다운로드
- 데이터 마스킹: 민감 정보 입력 최소화
7. gpt-oss와 Gemma 설치 방법
- gpt-oss (OpenAI)
- Ollama:
ollama run gpt-oss:20b - Hugging Face Transformers: Python
pipeline구성 - 요구 사양: 20b → 16GB RAM, 120b → 80GB GPU
- Ollama:
- Gemma (Google)
- Hugging Face에서 모델 다운로드 (
gemma-2b,gemma-7b) - LM Studio 또는 Vertex AI 통합 가능
- Gemma 3 270M: 초경량, 노트북에서도 실행 가능
- Hugging Face에서 모델 다운로드 (
8. 대표적인 사용 사례
- 기업
- 금융기관: 내부 보고서 자동 요약, 리스크 분석
- 제조사: 장비 매뉴얼 질의응답, 작업표준서 자동 생성
- 공공기관
- 행정기관: 법령·규정 문서 검색/요약
- 국방: 내부 작전 지침서 분석(보안 환경)
- 연구/교육
- 데이터 분석 교육용 AI 조교
- 연구 보고서 문서 초안 생성
9. 결론 및 제언
- 로컬 LLM은 보안·비용·커스터마이징 측면에서 기업·공공기관에 필수적인 기술
- gpt-oss, Gemma 같은 모델은 설치 용이성과 상업적 활용 가능성이 높음
- 보안 규제와 인프라를 고려해 단계적 도입 필요
- 다음 단계: 파일럿 프로젝트 → 내부 데이터셋 기반 fine-tuning → 조직 전반 확산
추천 모델 1. GPT-oss 시리즈
- gpt‑oss‑20b: 약 210억 개의 파라미터로 구성된 비교적 작은 모델입니다. 일반적인 노트북이나 데스크톱에서도 실행 가능하며, 특히 16GB RAM 또는 VRAM만 있으면 충분히 작동 가능
- gpt‑oss‑120b: 약 1170억 개의 파라미터로 구성된 고성능 모델입니다. 고사양 PC 혹은 워크스테이션급 환경(예: 총 80GB 이상의 RAM 또는 GPU + 시스템 메모리 조합)이 필요
- 라이선스 및 접근: 두 모델 모두 Apache 2.0 라이선스로 공개되어 있으며, Hugging Face, AWS, Azure, Ollama, LM Studio, vLLM 등 다양한 플랫폼을 통해 다운로드 및 실행 가능
- 설치 및 실행 방법:
- Ollama: 터미널에서
ollama run gpt-oss:20b명령 한 줄로 쉽게 시작할 수 있어 가장 간단한 방법 - LM Studio: GUI 환경으로 직관적인 설치 및 실행이 가능하며, OpenAI API 호환 로컬 서버도 지원
- Transformers (Hugging Face 통한 수동 실행):
transformers라이브러리를 사용해 Python 코드로 직접 파이프라인을 설정해 실행
- Ollama: 터미널에서
- 기술적 특징: 최신 딥러닝 기법인 Mixture-of-Experts (MoE) 아키텍처를 활용, 효율적인 추론과 비용 절감이 가능하며, 복잡한 작업(수학, 코딩, 에이전트 기능 등) 수행 능력 탁월
추천 모델 2. ChatGPT Agent
- ChatGPT Agent는 사용자의 PC 환경 일부(가상 브라우저, 파일, 툴 등)와 상호작용하며, 캘린더 확인, 슬라이드 생성, 파일 조작 등 복합 작업을 수행할 수 있는 AI 에이전트입니다. 물론 여전히 클라우드 기반이며, 완전 로컬 실행 모델이 아니라 가상 머신 등을 활용한 형태
- 즉, ‘노트북에 직접 설치되는 모델’과는 차이가 있으며, 사용자 PC에서 작업을 수행하도록 명령하는 형태
추천 모델 3. Codex CLI (개발자용)
- Codex CLI는 OpenAI가 2025년 4월에 Apache 2.0 라이선스로 GitHub에 공개한, 로컬에서 실행 가능한 터미널 기반 AI 코딩 도구입니다. 코드 작성, 테스트, PR 제안 등의 개발 작업을 지원하며,
codex-mini-latest라는 모델을 내부적으로 활용 - 이 방식은 가볍고 개발자 친화적인 작업에 적합하며, 콜드 API를 거치지 않고 로컬에서 완전 실행 가능한 점이 장점
요약 표
| 모델 / 도구 | 설치 가능 여부 | 특징 및 요구사항 | 주요 활용 용도 |
|---|---|---|---|
| gpt-oss-20b | 실제 로컬 설치 가능 | 16GB RAM 이상 필요, Ollama/LM Studio 통해 간편 실행 | 로컬 AI 챗봇, 개발 실험, 프라이버시 확보 |
| gpt-oss-120b | 실제 로컬 설치 가능 | 약 80GB RAM 필요 (고성능 PC 요망) | 고사양 로컬 AI 연구/작업 |
| ChatGPT Agent | 설치는 클라우드 기반 | AI가 사용자 PC와 상호작용, 멀티스텝 작업 수행 | 자동화된 에이전트형 작업 보조 |
| Codex CLI | 설치 가능 (개발자용) | 터미널 기반 코딩 에이전트, Apache 2.0 라이선스 | 로컬 코드 지원 및 생산성 향상 |
첫 포스팅: 25.08.24 / 포스트 문의: JUN (naebon@naver.com)

