2026.01.25 / 동준상.넥스트플랫폼 (naebon@naver.com)
핵심 요약 (Executive Summary)
이번 특강은 AI 도입에 따른 클라우드 아키텍처의 근본적인 변화를 분석하고, 파운데이션 모델(FM)과 데이터 흐름 기반의 서비스 구조, 그리고 이를 운영하기 위한 보안, 거버넌스, 비용 최적화 전략을 종합적으로 설명하는 강의 과정입니다.
전통적인 클라우드 아키텍처가 서버 자원의 효율성과 안정적인 애플리케이션 실행에 집중했다면, AI-네이티브 클라우드 아키텍처는 ‘워크로드’와 ‘데이터 흐름’을 중심으로 설계 기준이 완전히 전환되어야 합니다. AI 워크로드는 예측 불가능한 요청 패턴과 높은 데이터 의존성을 특징으로 하며, 이는 서버 중심 설계의 한계를 드러냅니다.
성공적인 AI 서비스를 위해서는 파운데이션 모델을 API 형태로 활용하되, 기업 고유의 데이터를 결합한 RAG(검색 증강 생성) 구조를 통해 신뢰성을 확보해야 합니다. 또한, AI 서비스가 실험 단계를 넘어 운영 단계로 진입함에 따라 가드레일(Guardrails) 기반의 보안 통제, 조직적 거버넌스, 그리고 토큰 단위의 세밀한 비용 관리가 통합된 설계가 필수적입니다.
커리큘럼
| 핵심 주제 | 주요 교육 내용 | 워크로드 유형/특성 |
| 1부. AI 워크로드 기준 클라우드 아키텍처 설계의 전환 | 서버 중심에서 워크로드 및 흐름 중심으로의 설계 기준 전환, 전통적 클라우드와 AI 구조 차이 분석, API 기반 AI 구조 및 상태(State) 저장 전략 | 추론(실시간/저지연), 학습(대용량/배치/고비용), 에이전트(상태 유지/맥락 지속/복합 작업) |
| 2부. 파운데이션 모델과 데이터 흐름 기반 AI 서비스 구조 | 파운데이션 모델(FM)의 정의 및 활용, 애플리케이션 오케스트레이터의 역할, RAG(검색 증강 생성) 구조와 벡터 데이터베이스 설계 | 데이터 의존적 추론, 외부 데이터 결합(RAG), 텍스트 분할 및 임베딩 파이프라인 |
| 3부. 보안·거버넌스·비용을 고려한 AI-네이티브 운영 설계 | AI 특화 보안 위협 대응, 입력/출력 가드레일 설계, 조직 차원의 AI 거버넌스 체계, 토큰 단위 비용 관리 및 최적화 | 통제 및 관리 중심 워크로드, 정책 기반 필터링, 사용량 기반 과금 패턴 분석 |
교재 다운로드 (PDF / 69p)
https://drive.google.com/file/d/1q3dS6Ku6jNuTGL9JyNi_uyHz6uV2h-D7/view?usp=sharing
1. AI 워크로드 중심의 아키텍처 전환
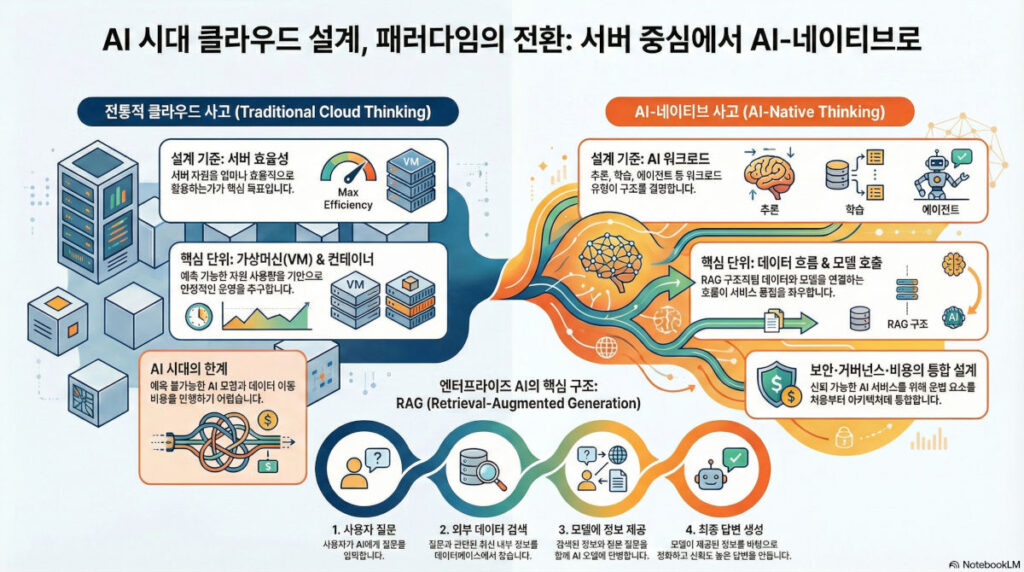
전통적 구조와 AI-네이티브 구조의 대비
전통적 클라우드는 VM과 컨테이너를 기본 단위로 하며 인프라와 애플리케이션의 경계가 명확하지만, AI는 인프라보다 워크로드의 특성이 구조를 결정합니다.
| 구분 | 전통적 클라우드 아키텍처 | AI-네이티브 클라우드 아키텍처 |
| 핵심 목표 | 서버 자원의 효율적 활용 | 워크로드 처리 및 데이터 흐름 최적화 |
| 기본 단위 | VM, 컨테이너 | AI 워크로드 (추론, 학습, 에이전트) |
| 확장 방식 | 서버 확장 중심 | API 호출 및 토큰 기반 확장 |
| 설계 초점 | 안정성 및 예측 가능성 | 가변적 요청 대응 및 지속적 튜닝 |
AI 워크로드의 3대 유형
각 워크로드는 요구 조건이 상이하므로 분리 설계가 필요합니다.
- 추론 (Inference): 실시간 응답이 중요하며, 짧고 빈번한 요청 패턴을 가집니다. 지연 시간 최소화와 캐싱 전략이 핵심입니다.
- 학습 (Training): 대규모 연산 자원을 배치 작업 형태로 사용하며, 단기간 고비용이 발생합니다. 운영 워크로드와 격리 설계가 필요합니다.
- 에이전트 (Agent): 이전 요청의 맥락(State)을 유지하며 복합 작업을 수행합니다. 상태 저장 위치와 보안 책임 범위 설정이 중요합니다.
2. 파운데이션 모델과 데이터 흐름 중심 설계
파운데이션 모델(FM)의 활용 구조
현대 AI 서비스는 모델을 직접 구축하기보다 클라우드에서 제공하는 관리형 FM을 API 형태로 활용하는 추세입니다.
- 역할 분리: 애플리케이션은 비즈니스 흐름을 제어하는 오케스트레이터 역할을 수행하고, 모델은 추론과 생성 기능에 집중하는 ‘느슨한 결합’ 구조를 지향합니다.
- 한계 극복: FM 단독 활용 시 발생하는 최신 정보 부재와 환각(Hallucination) 현상을 해결하기 위해 외부 데이터 연결이 필수적입니다.
RAG(Retrieval-Augmented Generation) 구조의 핵심 요소
엔터프라이즈 AI의 품질은 데이터 흐름 설계에 의해 결정됩니다.
- 데이터 파이프라인: 원천 데이터 수집, 정제, 텍스트 분할 및 임베딩 생성 과정을 거칩니다.
- 벡터 데이터베이스: 텍스트의 의미를 벡터로 변환하여 저장하고 유사도 기반 검색을 수행합니다. RAG 구조의 필수 구성 요소입니다.
- 검색 및 생성: 사용자 질문과 관련된 데이터를 벡터 DB에서 검색하여 모델에 전달함으로써 응답의 정확성과 신뢰성을 높입니다.
3. 보안, 거버넌스 및 비용 통합 운영 설계
AI 특화 보안 및 가드레일
AI 서비스는 프롬프트 인젝션과 같은 새로운 공격 벡터에 노출되어 있으며, 네트워크 중심의 기존 보안만으로는 불충분합니다.
- 입력 가드레일: 사용자 입력 사전 검증, 민감 정보 및 금지어 필터링을 통해 모델 호출 전 위험을 차단합니다.
- 출력 가드레일: 모델의 응답 내용이 규정을 준수하는지 검증하고, 답변의 톤과 범위를 통제하여 사용자 신뢰를 확보합니다.
AI 거버넌스 및 비용 관리
- 거버넌스 체계: 누가 어떤 모델을 사용하는지, 데이터 출처와 활용 범위는 어디까지인지 조직 차원에서 관리해야 합니다. 모델 사용 이력 및 정책 변경 이력에 대한 감사 추적이 포함됩니다.
- 비용 구조의 변화: 서버 기준의 사고에서 벗어나 토큰 및 호출 단위의 비용 관리가 필요합니다.
- 비용 발생 요인: 모델 호출 횟수, 응답 길이, 임베딩 생성, 벡터 저장 및 데이터 전송 비용.
- 최적화 전략: 불필요한 중복 호출 제거, Stateless 구조 활용, 비용 가시성 확보를 통한 지속 가능성 설계.
결론: AI-네이티브로의 사고 전환
AI-네이티브 아키텍처는 단순한 기술 도입이 아니라 설계 사고의 근본적 전환을 의미합니다. 서버 중심에서 흐름 중심으로, 그리고 성능 중심에서 통제 가능한 운영 중심으로 변화해야 합니다.
- 설계의 핵심: 워크로드가 아키텍처를 정의하며, 데이터·보안·비용은 설계 초기부터 분리 불가능한 요소로 다루어져야 합니다.
- 운영의 핵심: AI 운영의 성패는 모델의 성능보다 보안 가드레일과 거버넌스 체계를 통한 ‘통제력’과 비용 효율적인 ‘지속 가능성’에 달려 있습니다.