How to Build a Local AI Environment on Mac Mini Using Gemma 4
🎯 핵심 정리 (TL;DR)
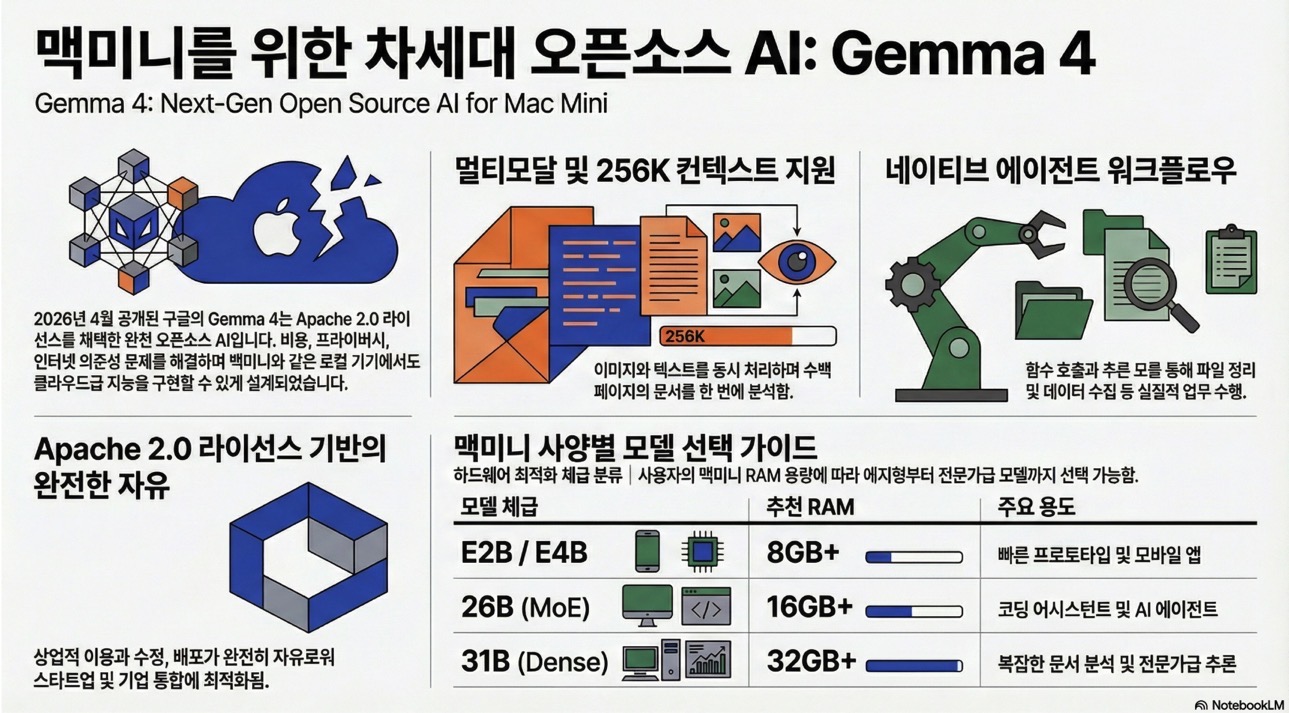
2026년 4월, 구글이 공개한 Gemma 4는 Apache 2.0 라이선스로 완전 오픈소스화된 차세대 AI 모델입니다. 맥미니 같은 로컬 환경에서도 멀티모달 처리, 256K 토큰 컨텍스트, 에이전트 워크플로우를 구현할 수 있어, 클라우드 의존 없이 ‘바이브코딩’을 실현하는 최적의 도구로 주목받고 있습니다.
이 글에서 다룰 내용:
- Gemma 4가 이전 세대와 다른 3가지 혁신
- 맥미니 사용자를 위한 모델 선택 가이드
- 오늘 바로 시작할 수 있는 바이브코딩 핸즈온 아이디어 3가지
예상 독자: 로컬 AI 환경을 구축하고 싶은 개발자, 맥미니로 AI 프로젝트를 시작하려는 입문자, 오픈소스 LLM 활용법을 찾는 실무자
왜 지금 Gemma 4인가? 로컬 AI의 게임체인저
문제: 클라우드 AI의 한계
많은 개발자들이 ChatGPT나 Claude 같은 클라우드 API에 의존하면서 세 가지 벽에 부딪힙니다.
- 비용 장벽: API 호출 횟수가 늘수록 급증하는 비용
- 프라이버시 리스크: 민감한 데이터를 외부 서버로 전송해야 하는 불안감
- 인터넷 의존성: 오프라인 환경이나 네트워크 불안정 시 작업 중단
특히 바이브코딩처럼 “즉각적인 피드백과 실험”을 중시하는 개발 스타일에서는, API 지연이나 비용 걱정 없이 무제한으로 시도할 수 있는 환경이 필수적입니다.
해결책: Gemma 4의 3가지 혁신
구글이 2026년 4월 2일 발표한 Gemma 4는 이 문제들을 정면으로 해결합니다.
1. Apache 2.0 라이선스로 완전한 자유
기존 Gemma 시리즈의 독자 라이선스에서 Apache 2.0으로 전환하면서, 상업적 이용·수정·배포가 완전히 자유로워졌습니다. 스타트업이 자사 제품에 내장하거나, 기업이 내부 시스템에 통합해도 라이선스 비용이나 제약이 전혀 없습니다.
# 예시: Gemma 4를 상업 프로젝트에 자유롭게 활용
from ollama import chat
response = chat(model='gemma4:26b', messages=[
{'role': 'user', 'content': '고객 문의 이메일을 분석해 긴급도를 분류해줘'}
])
# 라이선스 걱정 없이 실서비스 배포 가능2. 멀티모달 + 256K 컨텍스트: 실전 활용도 극대화
- 멀티모달 능력: 텍스트+이미지 동시 처리 (소형 모델은 오디오도 지원)
- OCR·차트 분석: 스크린샷이나 문서 이미지를 바로 읽어 코드로 변환
- 256K 토큰 컨텍스트: 수백 페이지 문서나 대규모 코드베이스를 한 번에 분석
예를 들어, 복잡한 API 문서 PDF 전체를 입력하고 “이 API로 사용자 인증 구현하는 Python 예제 만들어줘”라고 요청하면, 문서 전체 맥락을 이해한 정확한 코드를 받을 수 있습니다.
3. 에이전트 워크플로우: AI가 실제로 일하게 만들기
Gemma 4는 단순 질의응답을 넘어 함수 호출(Function Calling)과 추론 모드를 네이티브 지원합니다. 이를 통해:
- 파일 시스템 탐색 후 자동 정리
- 외부 API 호출하여 데이터 수집
- 복잡한 논리 문제를 단계별로 사고하며 해결
# 에이전트 예시: 파일 정리 자동화
def analyze_files(file_list):
prompt = f"""
다음 파일들을 종류별로 분류하고 정리 계획을 JSON으로 작성해줘:
{file_list}
"""
plan = chat(model='gemma4:26b', messages=[{'role': 'user', 'content': prompt}])
return plan # {"images": [...], "documents": [...], "code": [...]}맥미니 사용자를 위한 Gemma 4 모델 선택 가이드
Gemma 4는 사용 환경에 따라 3가지 체급으로 제공됩니다.
| 모델 | 파라미터 | 주요 특징 | 추천 맥미니 사양 | 적합한 용도 |
|---|---|---|---|---|
| Gemma 4 E2B/E4B | 2.3B / 4.5B | 에지 최적화, 오디오 입력 지원 | 8GB+ RAM | 빠른 프로토타입, 모바일 앱 |
| Gemma 4 26B (MoE) | 26B (활성 ~4B) | Mixture-of-Experts로 속도+지능 양립 | 16GB+ RAM | 코딩 어시스턴트, 에이전트 |
| Gemma 4 31B (Dense) | 30.7B | 최고 추론력, 256K 컨텍스트 | 32GB+ RAM | 복잡한 문서 분석, 전문가급 작업 |
추천 시나리오:
- M2/M3 맥미니 (16GB): 26B MoE 모델 + 4비트 양자화로 쾌적한 코딩 어시스턴트 구축
- M4 맥미니 (32GB): 31B Dense 모델로 대규모 문서 분석 및 복잡한 에이전트 워크플로우
오늘 바로 시작하는 바이브코딩 핸즈온 3가지
핸즈온 1: 내 사진으로 시를 쓰는 ‘AI 감성 스토리텔러’
목표: 로컬 사진을 Gemma 4에 입력하면 감성적인 시나 SNS 캡션을 생성하는 프로그램 만들기
왜 이 프로젝트인가?
코드가 단순한 명령이 아니라 “내 추억과 AI 창의력을 연결하는 감성 매개체”가 되는 경험을 합니다. 외부 업로드 없이 내 컴퓨터에서 안전하게 실행되는 것도 큰 장점입니다.
핵심 기술:
- Gemma 4의 멀티모달 이미지 이해
- 140개 언어 지원으로 자연스러운 한글 생성
- 로컬 실행으로 프라이버시 보장
간단한 구현 단계:
# 1. Ollama로 Gemma 4 멀티모달 모델 설치
# ollama pull gemma4:e4b
# 2. 이미지+프롬프트로 시 생성
from ollama import chat
with open('my_photo.jpg', 'rb') as f:
image_data = f.read()
response = chat(
model='gemma4:e4b',
messages=[{
'role': 'user',
'content': '이 사진을 보고 느껴지는 감성으로 짧은 시를 한글로 써줘',
'images': [image_data]
}]
)
print(response['message']['content'])예상 결과:
“석양 빛에 물든 카페 창가 / 따뜻한 라떼 한 잔의 여유 / 오늘도 천천히 흘러간다”
핸즈온 2: 지저분한 다운로드 폴더를 정리하는 ‘AI 파일 비서’
목표: 다운로드 폴더의 파일명을 분석해 자동으로 분류 계획을 세워주는 에이전트
왜 이 프로젝트인가?
AI가 클라우드 너머가 아닌 “내 삶의 실제 문제를 해결하는 파트너”임을 체감합니다. 파일 정리라는 일상적 작업을 AI와 대화하듯 자동화하며 실용적 성취감을 얻습니다.
핵심 기술:
- 에이전트 워크플로우와 추론 모드
- 파일명 패턴 분석 능력
- 긴 컨텍스트로 수백 개 파일 동시 처리
간단한 구현 단계:
import os
from ollama import chat
# 1. 파일 목록 수집
download_folder = os.path.expanduser('~/Downloads')
files = os.listdir(download_folder)
# 2. Gemma 4에 분류 계획 요청
prompt = f"""
다음 파일들을 '이미지', '문서', '코드', '기타'로 분류하고,
각 파일을 어느 폴더로 이동할지 JSON 형식으로 계획을 세워줘:
{chr(10).join(files[:50])} # 처음 50개 파일
"""
response = chat(model='gemma4:26b', messages=[
{'role': 'user', 'content': prompt}
])
print(response['message']['content'])예상 결과:
{
"images": ["vacation_2026.jpg", "screenshot_001.png"],
"documents": ["Gemma4_Report.pdf", "invoice_april.docx"],
"code": ["test_script.py", "config.json"],
"others": ["random_file.tmp"]
}심화 과제: 실제로 shutil.move()로 파일을 이동시키는 코드 추가
핸즈온 3: 긴 유튜브 강의를 요약하는 ‘나만의 코딩 튜터’
목표: 1시간 분량 코딩 강의 자막 전체를 입력하고, 핵심 개념 3가지와 예제 코드를 받기
왜 이 프로젝트인가?
정보 홍수 속에서 길을 잃기 쉬운 입문자에게 AI가 ‘개인 맞춤형 튜터’가 됩니다. 방대한 정보를 내 눈높이로 가공하며 학습 장벽을 스스로 허무는 경험을 합니다.
핵심 기술:
- 256K 토큰 컨텍스트로 긴 자막 전체 분석
- 강력한 추론과 코딩 능력
- Apache 2.0 라이선스로 상업 서비스화 가능
간단한 구현 단계:
# 1. 유튜브 자막을 텍스트 파일로 저장 (yt-dlp 등 활용)
# 2. 자막 읽고 요약 요청
with open('lecture_transcript.txt', 'r') as f:
transcript = f.read()
prompt = f"""
다음은 Python 코딩 강의의 전체 스크립트입니다.
초보자를 위해:
1. 핵심 개념 3가지를 한 줄씩 요약
2. 가장 중요한 개념의 실행 가능한 Python 예제 코드 작성
강의 스크립트:
{transcript}
"""
response = chat(model='gemma4:31b', messages=[
{'role': 'user', 'content': prompt}
])
print(response['message']['content'])예상 결과:
핵심 개념:
1. 리스트 컴프리헨션은 for 루프를 한 줄로 압축하는 문법
2. enumerate()로 인덱스와 값을 동시에 얻을 수 있음
3. try-except로 예외 처리하여 프로그램 중단 방지
예제 코드:
numbers = [1, 2, 3, 4, 5]
squared = [n**2 for n in numbers if n % 2 == 0]
print(squared) # [4, 16]결론: 당장 시작하기 위한 체크리스트
Gemma 4는 “로컬 환경에서 클라우드급 지능”을 실현하려는 모든 개발자에게 현존 최강의 오픈소스 선택지입니다. 바이브코딩의 핵심인 “즉각적 피드백과 무제한 실험”을 비용 걱정 없이 구현할 수 있습니다.
오늘 당장 해야 할 3가지
- 환경 구축 (10분)
# Ollama 설치 (macOS)
brew install ollama
# Gemma 4 모델 다운로드
ollama pull gemma4:26b # 16GB RAM 맥미니
# 또는
ollama pull gemma4:31b # 32GB RAM 맥미니- 첫 번째 핸즈온 실행 (30분)
- 위의 ‘사진으로 시 쓰기’ 프로젝트부터 시작
- 내 사진 1장으로 AI의 멀티모달 능력 체감
- 코드를 수정하며 프롬프트 엔지니어링 연습
- 커뮤니티 참여 및 확장 (지속)
- Hugging Face에서 Gemma 4 양자화 모델 탐색
- GitHub에서 Gemma 4 에이전트 예제 코드 포크
- 자신만의 바이브코딩 프로젝트를 블로그나 SNS에 공유
다음 단계 아이디어
- 개인 지식 베이스 구축: Obsidian 노트를 Gemma 4에 연결해 개인 AI 어시스턴트 만들기
- 코드 리뷰 봇: GitHub PR을 자동으로 분석하고 개선점 제안하는 에이전트
- 음성 메모 → 할 일 자동 등록: 오디오 입력 지원 모델로 음성을 텍스트+작업으로 변환
참고자료
공식 문서 및 다운로드
기술 세미나 및 커뮤니티
- Google Cloud Next 2026 – Gemma 4 기술 세션 다시보기
- GitHub – Gemma 4 공식 예제 코드
- Reddit r/LocalLLaMA – 로컬 AI 커뮤니티
추가 학습 자료
- “Gemma 4 벤치마크 분석” – Arena AI 성능 비교
- “Apple Silicon에서 LLM 최적화하기” – MLX 프레임워크 가이드
- “에이전트 워크플로우 패턴” – LangChain + Gemma 4 튜토리얼
관련 도구
- Ollama: 로컬 LLM 실행 환경 (가장 추천)
- MLX: Apple Silicon 최적화 프레임워크
- LM Studio: GUI 기반 로컬 LLM 관리 도구
- yt-dlp: 유튜브 자막 추출 도구
이 글이 도움이 되셨나요? Gemma 4로 만든 첫 프로젝트를 댓글로 공유해주세요! 함께 바이브코딩의 즐거움을 나눠봅시다. 🚀
태그: #Gemma4 #로컬AI #바이브코딩 #오픈소스LLM #맥미니 #애플실리콘 #AI코딩 #멀티모달AI #에이전트워크플로우

