

2026.03.31 / 동준상.넥스트플랫폼
(AWS SAA, AWS AIF, GCP GenAI Leader)
이번 포스트는 Anthropic의 Labs 팀 소속 Prithvi Rajasekaran이 작성한 “장기 실행 애플리케이션 개발을 위한 하네스(Harness) 설계”에 관한 연구 내용을 종합한 브리핑 문서입니다. 자율형 에이전트의 성능을 극대화하기 위한 구조적 접근 방식과 실험 결과, 그리고 모델 진화에 따른 전략적 통찰을 담고 있습니다.
1. 핵심 요약 (Executive Summary)
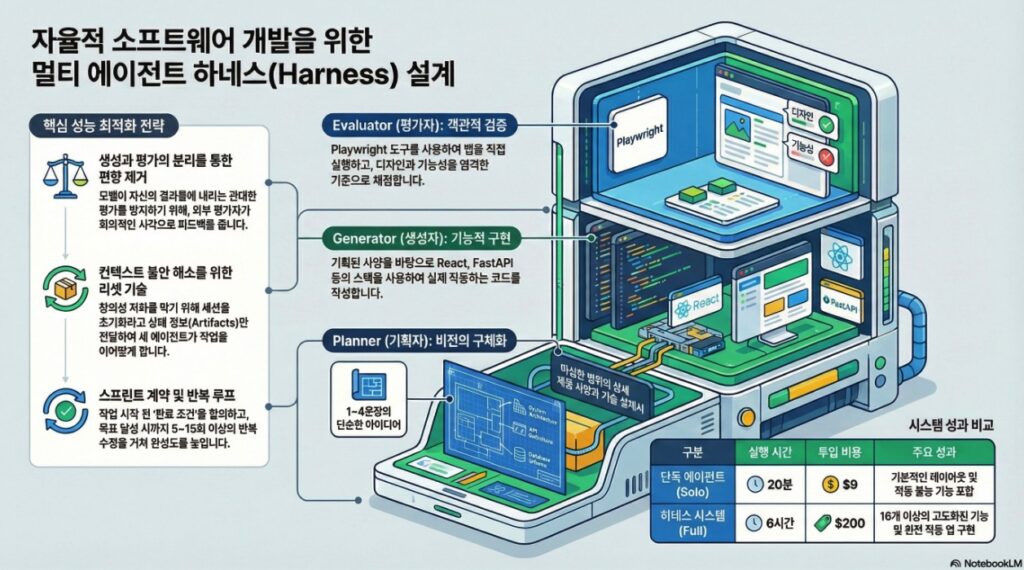
Anthropic의 최근 연구에 따르면, 프론트엔드 디자인 및 풀스택 소프트웨어 엔지니어링과 같은 복잡하고 장기적인 과업에서 Claude의 성능을 극대화하기 위해서는 정교한 **하네스 설계(Harness Design)**가 필수적입니다. 단순히 프롬프트 엔지니어링에 의존하는 단일 에이전트 방식은 한계에 봉착하며, 이를 극복하기 위해 제안된 핵심 전략은 다음과 같습니다.
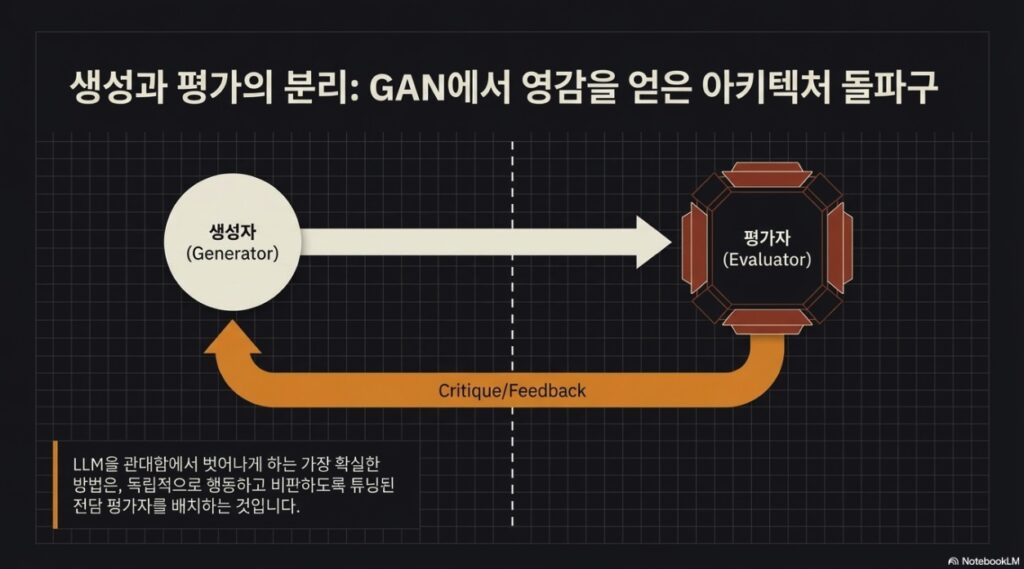
- 다중 에이전트 아키텍처: 생성적 적대 신경망(GAN)에서 영감을 얻은 **생성자(Generator)**와 평가자(Evaluator) 구조를 통해 에이전트의 자기 평가 편향을 제거하고 산출물의 품질을 비약적으로 향상시킵니다.
- 문맥 관리 최적화: 모델이 문맥 창의 한계에 도달할 때 발생하는 ‘문맥 불안(Context Anxiety)’과 응집력 저하를 해결하기 위해 **문맥 리셋(Context Resets)**과 자동 압축(Automatic Compaction) 기술을 전략적으로 활용합니다.
- 주관적 가치의 객관화: 디자인과 같은 주관적인 영역을 평가하기 위해 구체적인 채점 기준(디자인 품질, 독창성, 정밀도, 기능성)을 도입하여 에이전트가 개선할 수 있는 구체적인 피드백 루프를 형성합니다.
- 모델 발전에 따른 하네스 진화: 모델의 성능(예: Claude Opus 4.5에서 4.6으로의 진화)이 향상됨에 따라 복잡한 하네스 구조(예: 스프린트 구조)는 간소화될 수 있으나, 기획 및 평가 에이전트의 가치는 여전히 유효합니다.
| 프로젝트명 | 사용된 모델 | 하네스 구조 |
| 2D 레트로 게임 메이커 (Full Harness) | Claude Opus 4.5 | 3개 에이전트 시스템 (플래너, 생성기, 평가자) |
| 브라우저 기반 디지털 오디오 워크스테이션 (DAW) | Claude Opus 4.6 | v2 하네스 (플래너, 생성기, 통합 평가자 – 스프린트 구조 제거) |
| 2D 레트로 게임 메이커 (Solo) | Claude Opus 4.5 | 단일 에이전트 (Solo) |
2. 기존 에이전트 구현의 한계
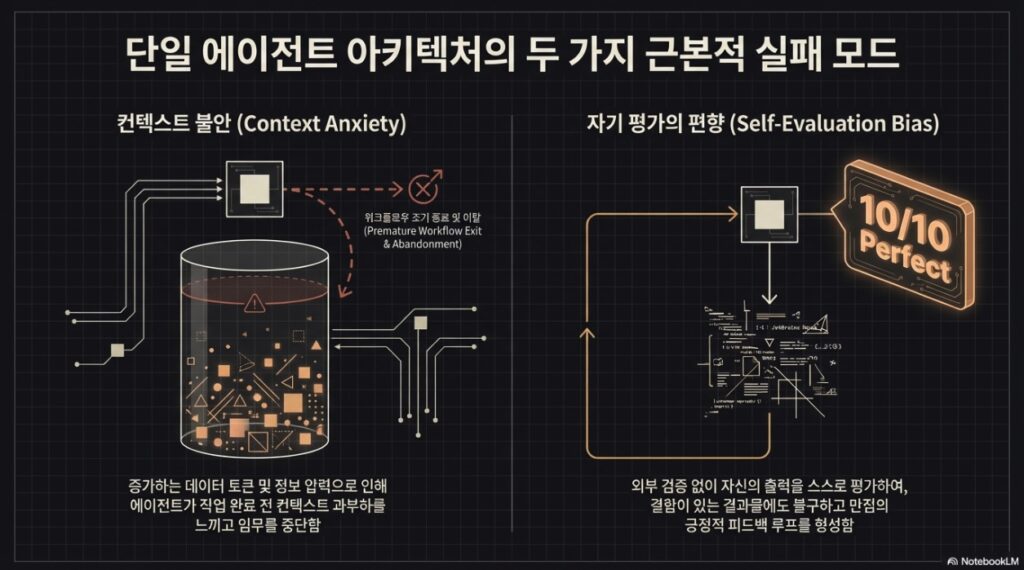
단순한 에이전트 구현 방식은 복잡한 작업을 수행할 때 두 가지 주요 실패 모드에 직면합니다.
2.1 문맥 불안 및 응집력 상실
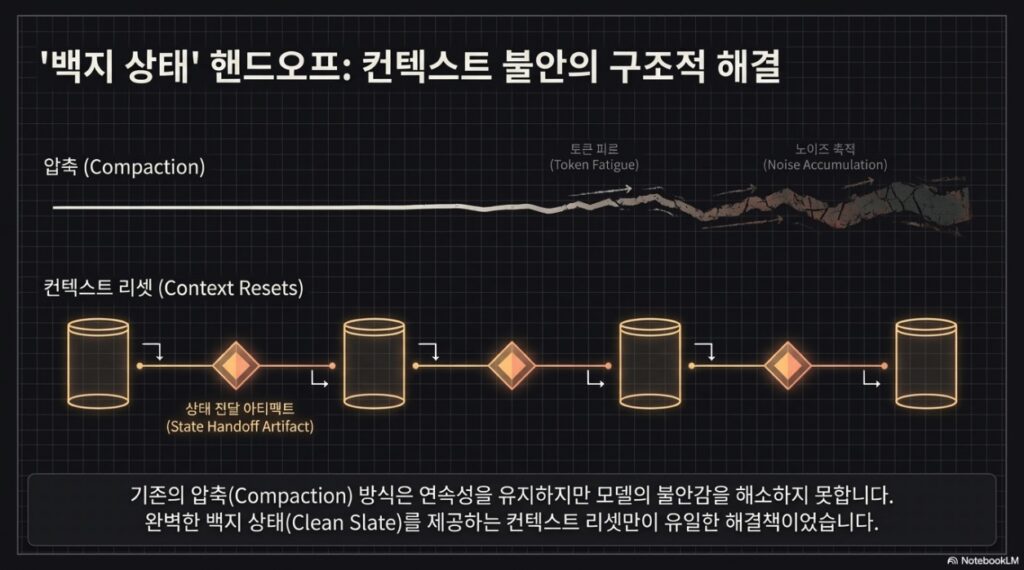
모델은 문맥 창이 채워짐에 따라 작업의 일관성을 잃거나, 문맥 한계에 도달할 것을 우려해 작업을 조기에 마무리하려는 ‘문맥 불안(Context Anxiety)’ 증상을 보입니다.
- 해결책: 문맥 창을 완전히 비우고 이전 에이전트의 상태를 구조화된 핸드오프(Handoff) 아티팩트로 전달하는 ‘리셋’ 방식이 효과적입니다. 단순히 이전 대화를 요약하는 ‘압축’ 방식은 에이전트에게 깨끗한 상태를 제공하지 못해 문맥 불안을 완전히 해소하지 못합니다.
2.2 자기 평가의 편향성
에이전트에게 자신의 작업물을 평가하도록 요청하면, 인간이 보기에 품질이 평범하더라도 지나치게 자신감 있게 칭찬하는 경향이 있습니다. 특히 이진 테스트가 불가능한 디자인 영역에서 이러한 현상이 두드러집니다.
- 해결책: 작업을 수행하는 에이전트와 이를 비판적으로 평가하는 에이전트를 분리해야 합니다. 독립적인 평가자를 ‘회의적’으로 튜닝하는 것이 생성자 스스로 비판적이 되도록 만드는 것보다 훨씬 효과적입니다.
3. 프론트엔드 디자인: 주관적 품질의 정량화
주관적인 디자인 영역에서 Claude가 “안전하고 예측 가능한” 레이아웃을 벗어나게 하기 위해 네 가지 채점 기준을 도입했습니다.
| 평가 기준 | 상세 내용 |
| 디자인 품질 (Quality) | 전체적인 응집력, 색상, 타이포그래피, 레이아웃이 독특한 분위기와 아이덴티티를 형성하는가? |
| 독창성 (Originality) | 템플릿이나 라이브러리 기본값이 아닌 의도적인 창의적 선택이 보이는가? (AI 특유의 패턴 지양) |
| 정밀도 (Craft) | 타이포그래피 계층 구조, 간격의 일관성, 색상 조화 등 기술적 실행력이 우수한가? |
| 기능성 (Functionality) | 심미성과 별개로 사용자가 인터페이스를 이해하고 주요 동작을 완료할 수 있는가? |
이 기준을 바탕으로 생성자와 평가자가 반복적인 피드백 루프(5~15회 반복)를 거치면서, 모델은 점진적인 개선을 넘어 기존의 방식을 완전히 뒤엎는 창의적인 도약(예: 2D 사이트를 3D 공간 경험으로 재설계)을 보여주었습니다.
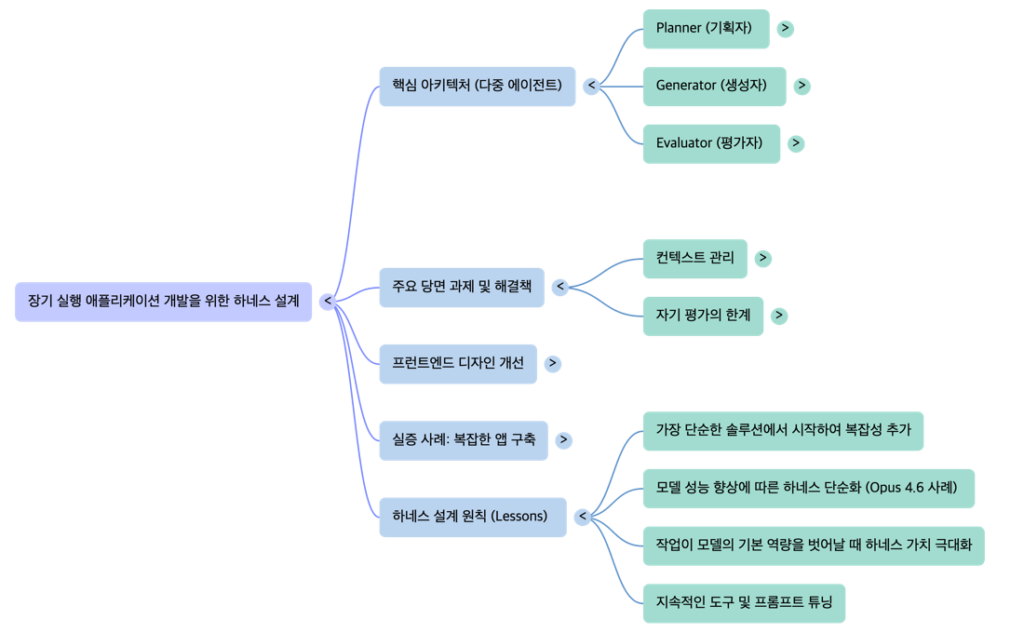
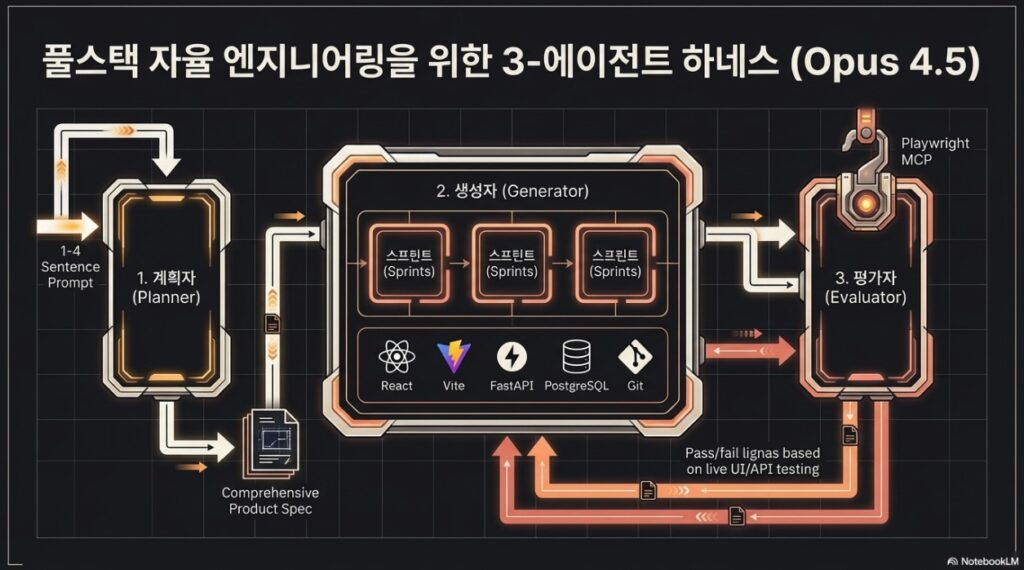
4. 풀스택 코딩을 위한 3단계 에이전트 아키텍처
장기 실행 코딩 에이전트는 기획, 생성, 평가의 역할을 분담하는 구조로 설계되었습니다.
4.1 주요 역할 정의
- 기획자 (Planner): 간단한 프롬프트를 확장하여 상세한 제품 사양서를 작성합니다. 세부 기술 구현보다는 제품의 문맥과 고차원적 디자인에 집중하며, AI 기능 통합 기회를 발굴합니다.
- 생성자 (Generator): 사양서의 기능을 한 번에 하나씩 구현합니다. React, Vite, FastAPI 등의 스택을 사용하며, 각 단계 종료 후 자가 평가를 거쳐 QA에 전달합니다.
- 평가자 (Evaluator): Playwright MCP를 사용하여 실제 실행 중인 애플리케이션을 클릭하고 테스트합니다. 버그를 찾고 사전에 합의된 ‘스프린트 계약’ 기준에 따라 엄격하게 채점합니다.
4.2 실험 결과 비교: Solo 에이전트 vs. Full 하네스
작업: 2D 레트로 게임 제작 도구 구축
| 구분 | 소요 시간 | 비용 | 결과 품질 |
| Solo 에이전트 | 20분 | $9 | 레이아웃 낭비, 기능적 결함(실제 게임 플레이 불가), 유연성 부족 |
| Full 하네스 | 6시간 | $200 | 16가지 기능 사양 충실 구현, 일관된 시각적 아이덴티티, 실제 작동하는 물리 엔진 및 AI 보조 설계 기능 포함 |
5. 하네스의 진화와 최적화 전략
모델이 발전함에 따라 하네스의 복잡성을 줄이는 최적화 과정이 필요합니다.
5.1 Claude Opus 4.5에서 4.6으로의 변화
- 스프린트 구조 제거: Opus 4.6은 더 긴 시간 동안 에이전트 작업을 지속하고 계획할 수 있는 능력이 향상되어, 작업을 작은 단위로 쪼개는 ‘스프린트’ 구조 없이도 2시간 이상의 연속적인 빌드가 가능해졌습니다.
- 평가자의 역할 변화: 모델의 기본 능력이 향상됨에 따라 간단한 작업에서 평가자는 불필요한 오버헤드가 될 수 있습니다. 그러나 모델의 한계점에 있는 복잡한 작업에서는 여전히 실질적인 성능 향상을 제공합니다.
5.2 최신 하네스(V2)의 성과 (디지털 오디오 워크스테이션 제작 사례)
- 총 소요 시간: 약 4시간 (빌드 1라운드에만 2시간 이상 소요)
- 총 비용: $124.70
- 성과: 브라우저 기반의 기능적 DAW 구축. 평가자가 “오디오 녹음 기능이 스텁(stub)으로만 구현됨”, “시각적 효과 편집기 부재” 등의 정밀한 결함을 잡아내어 개선을 유도했습니다.
6. 결론 및 향후 전망
본 연구를 통해 도출된 핵심 교훈은 다음과 같습니다.
- 하네스의 가변성: 하네스의 모든 구성 요소는 모델이 스스로 할 수 없는 것에 대한 가정을 바탕으로 합니다. 모델이 발전함에 따라 불필요한 하네스는 제거하고, 새로운 모델이 도달할 수 있는 더 높은 수준의 성능을 위해 하네스를 재설계해야 합니다.
- 평가자 튜닝의 중요성: 에이전트가 훌륭한 QA 역할을 수행하게 하려면 단순한 프롬프트만으로는 부족하며, 개발자가 에이전트의 로그를 읽고 판단이 엇갈리는 부분을 지속적으로 튜닝하는 루프가 필요합니다.
- 엔지니어링의 역할: 모델 성능이 향상된다고 해서 하네스 설계의 중요성이 줄어드는 것은 아닙니다. 오히려 엔지니어들은 향상된 기본 모델을 바탕으로 더 복잡하고 흥미로운 하네스 조합을 찾아내어 AI의 한계를 계속해서 확장해 나가야 합니다.

