2026.04.20 / 동준상.넥스트플랫폼
(AWS SAA, AWS AIF, GCP GenAI Leader)

이번 포스트는 한국생산성본부 (KPC)의 정규과정 학습자를 위해 작성됐습니다. 이번 교육 과정에서는 AI 네이티브 클라우드의 아키텍처 측면에서의 특징에 대해 알아보고 기업용 AI 서비스 개발과 운영에 적합한 설계 방법을 함께 알아봅니다.
KPC | AI 클라우드 서비스 도입 및 활용 (과정 상세정보 및 수강신청)
https://www.kpc.or.kr/PTWED003_dtil_view.do?ecno=47716
수강고객사
- 기상청
- 인실리코
- KB국민카드
- 한국국방연구원
- 한국지역정보개발원
핵심 요약 (Executive Summary)
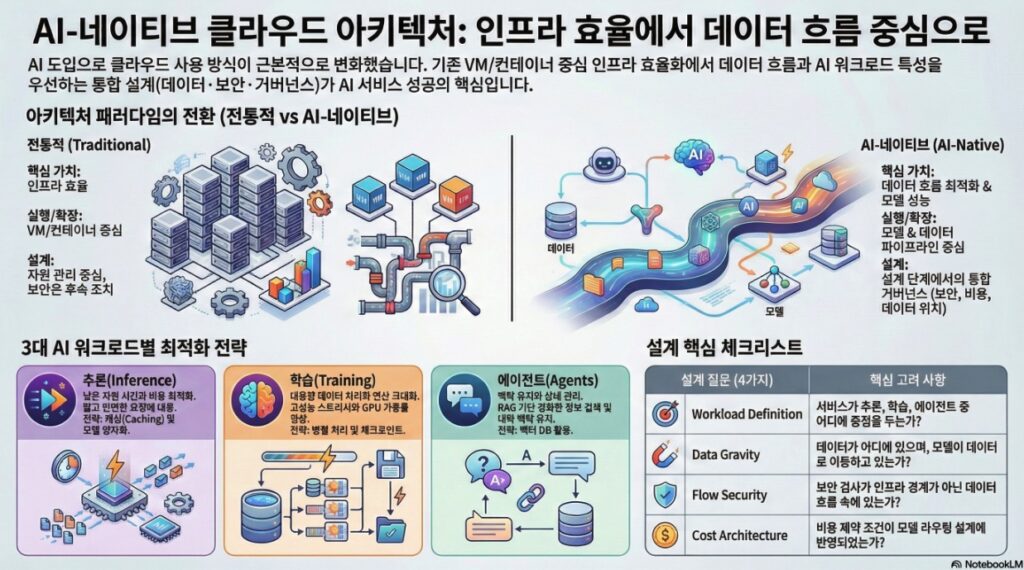
현재 클라우드 패러다임은 단순한 자원 효율화에서 데이터 흐름과 모델 성능 중심으로 근본적인 변화를 맞이하고 있습니다. 기존의 VM 및 컨테이너 기반 설계는 예측 불가능한 AI 추론 요청 패턴과 기하급수적으로 증가하는 데이터 이동 비용을 감당하기에 한계가 있습니다.
성공적인 AI-네이티브 전환을 위한 3대 핵심 전략
- AI 워크로드별 최적화: 추론(지연 시간), 학습(처리량), 에이전트(맥락 유지)라는 세 가지 핵심 워크로드의 특성을 이해하고 분리 설계
- 디커플링(Decoupling): 비즈니스 로직(애플리케이션)과 생성 모델(Inference Layer)을 느슨하게 결합하여 유연성과 확장성을 확보
- 통합 거버넌스: 보안, 비용(토큰 관리), 데이터 위치는 사후 조치가 아닌 설계 초기 단계에서 통합적으로 고려
AI 클라우드 아키텍처 워크로드 비교
| 워크로드 유형 | 핵심 목표 | 아키텍처 특징 | 주요 비용 요인 |
| 추론 (Inference) | 빠른 응답 속도 및 낮은 지연 시간 확보 | Stateless 구조, 수평적 확장(Auto-scaling) 및 장애 복원 중심, 캐싱(Caching) 레이어 활용 | API 호출 빈도, 입력 및 출력 토큰 사용량에 따른 비용 누적 |
| 에이전트 (Agents) | 상태와 맥락(Context) 유지 및 복합적 상호작용 수행 | Stateful 구조, 벡터 데이터베이스(Vector DB) 통합, 외부 도구(APIs)와의 연동 체계 | 맥락 유지를 위한 긴 토큰 처리 비용, 벡터 검색 및 데이터 이동 비용 |
| 학습 (Training) | 높은 처리량(Throughput) 및 컴퓨팅 자원 효율 최적화 | 배치(Batch) 작업 구조, 병렬 파일 시스템 기반 고속 데이터 공급, 체크포인트 저장 전략 | 대규모 GPU 컴퓨팅 자원 및 고성능 스토리지 사용량 |
사전설문 및 워크북 다운로드
AI 클라우드 아키텍처 과정 사전설문
https://forms.gle/8DuP48Tma4txd4fg8
리서치용 AI 도구: AIGrape – GPT, Gemini, Claude, Perplexity 통합 플랫폼
https://www.aigrape.net/
AI 핸즈온 랩 | AI 네이티브 클라우드 실무 활용 마스터
https://nextplatform.net/ai-native-cloud-handson-vertex-ai-master/



AI와 클라우드 산업의 기술 발전 연대기 (build by Jay using Claude Design)
https://nextplatform.net/ai-cloud-chronicle.html



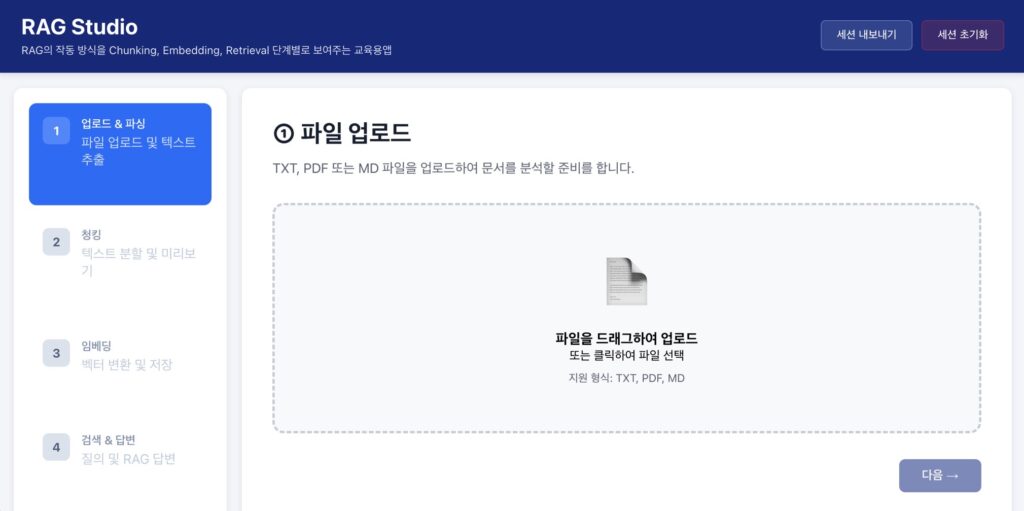
RAG Studio:
RAG 작동 방식의 Chunking, Embedding, Retrieval 단계별 시각화
https://nxp-rag-studio.vercel.app/
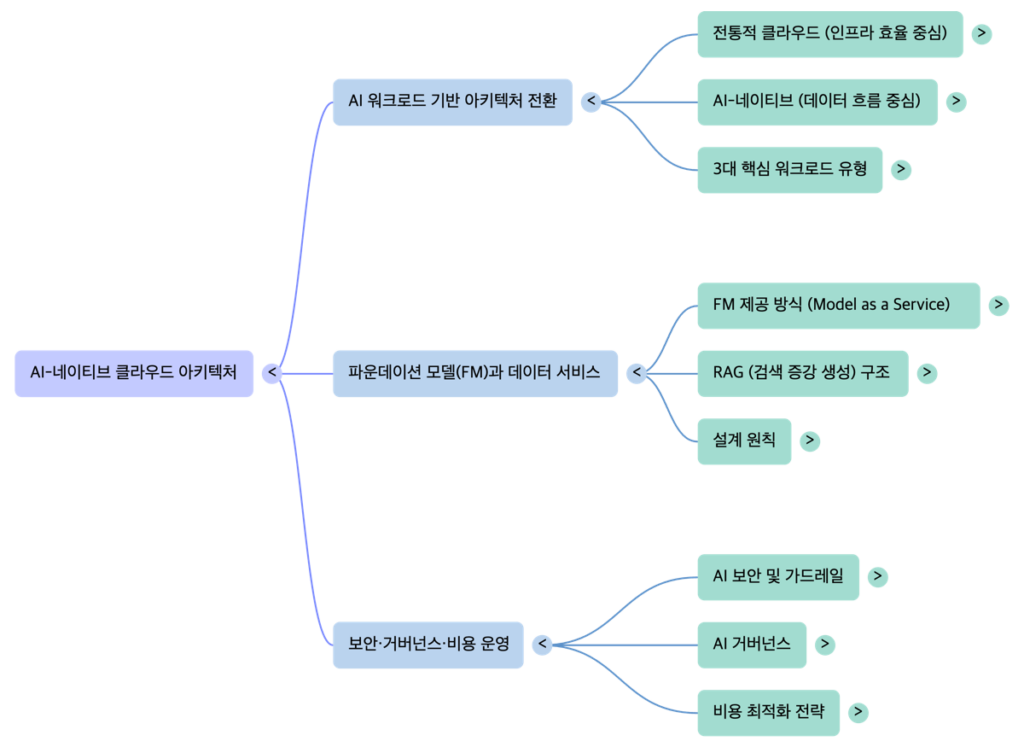
1. 클라우드 아키텍처의 패러다임 전환: 계산 중심에서 데이터 흐름 중심으로
1.1 전통적 클라우드와 AI-네이티브 클라우드 비교
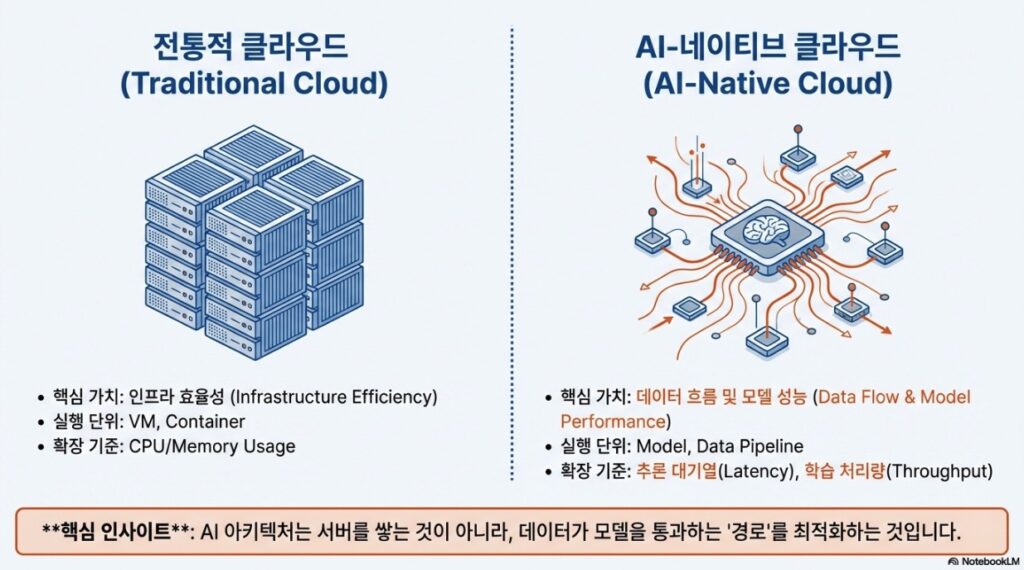
전통적인 클라우드 설계가 인프라의 안정적인 활용에 집중했다면, AI-네이티브 설계는 모델 호출과 데이터의 유기적 연결을 최우선으로 합니다.
| 카테고리 | 전통적 클라우드 (Traditional Cloud) | AI-네이티브 클라우드 (AI-Native Cloud) |
| 핵심 가치 | 인프라 효율성 (Infrastructure Efficiency) | 데이터 흐름 및 모델 성능 (Data Flow & Model Performance) |
| 실행 단위 | VM, 컨테이너 | 모델, 데이터 파이프라인 |
| 확장 기준 | CPU/Memory 사용량, 트래픽 | 추론 대기열, 학습 데이터 처리량 |
| 설계 우선순위 | 상태 관리의 단순화 | 맥락(Context) 유지 및 데이터 이동 최소화 |
1.2 기존 설계의 한계와 마찰 지점
- 예측 불가한 워크로드: 정적인 웹 트래픽과 달리 AI 추론 요청은 패턴 예측이 어렵고 모델 호출 지연(Latency)이 사용자 경험에 치명적인 영향을 미칩니다.
- 비용 구조의 변화: 인프라 확장이 선형적 비용 증가로 이어지는 기존 방식과 달리, AI는 데이터 이동 및 모델 호출 빈도에 따라 기하급수적인 비용이 발생할 수 있습니다.
2. AI 워크로드의 3대 핵심 유형 및 설계 특징

AI 서비스는 단일 구조가 아닌 워크로드의 특성에 따라 세분화된 접근이 필요합니다.
2.1 추론 (Inference) 중심 워크로드
- 특징: 짧고 빈번한 요청 패턴, 낮은 지연 시간(Low Latency) 요구.
- 설계 전략:
- Stateless 구조: 각 요청을 독립적으로 처리하여 수평적 확장과 장애 복구에 유리하게 설계.
- 최적화 기법: 모델 로딩 시간을 최소화하는 온디맨드 리소스 전략, 비용 누락을 막기 위한 캐싱(Caching) 및 모델 양자화(Quantization) 고려.
2.2 학습 (Training) 중심 워크로드
- 특징: 대용량 데이터 처리, 장시간 고성능 연산, 처리량(Throughput) 중심.
- 설계 전략:
- 배치(Batch) 작업 구조: 대규모 작업을 묶어 자원 사용률을 극대화.
- 고속 스토리지: 데이터 I/O 속도 확보를 위한 병렬 파일 시스템 및 고성능 연산 자원(GPU 등)의 효율적 스케줄링.
- 회복 탄력성: 장시간 학습 중단에 대비한 체크포인트(Checkpoint) 저장 및 복구 전략.
2.3 에이전트 (Agents) 중심 워크로드
- 특징: 상태(State)와 맥락(Context)의 지속적 유지, 복합적 상호작용.
- 설계 전략:
- Memory Layer 통합: 대화 기록 및 지식 베이스를 위한 벡터 데이터베이스(Vector DB) 통합.
- 보안 및 권한 제어: 에이전트가 접근 가능한 데이터 범위와 API 권한 제어가 아키텍처의 핵심.
3. 파운데이션 모델(FM)과 데이터 흐름 설계

3.1 클라우드 기반 관리형 모델 활용
직접 모델을 구축하는 방식 대신, 클라우드 벤더가 제공하는 관리형 파운데이션 모델(Managed FM)을 API 형태로 활용하는 것이 일반화되고 있습니다.
- 장점: 인프라 관리 부담 제거(Infra-less), 보안 및 고가용성 기본 내장, 빠른 서비스 배포.
- 플랫폼 사례:
- AWS Bedrock: 단일 모델 종속을 피하고 다양한 FM(Titan, Claude, Llama 등)을 골라 쓸 수 있는 플랫폼적 접근 제공.
- Google Cloud Vertex AI: Gemini 모델과 자사 데이터 생태계(BigQuery 등)를 결합하여 분석과 생성을 통합.
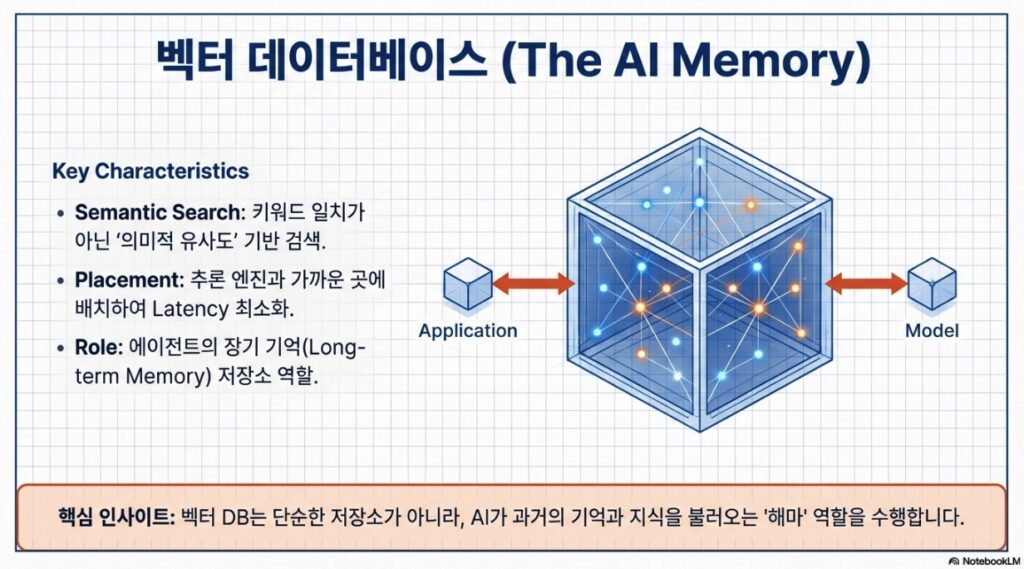
3.2 RAG(검색 증강 생성) 구조의 도입
모델 단독 활용 시 발생하는 최신 정보 미반영 및 환각 현상을 해결하기 위해 RAG 구조는 엔터프라이즈 AI의 표준으로 자리 잡고 있습니다.
데이터 흐름 파이프라인 단계:
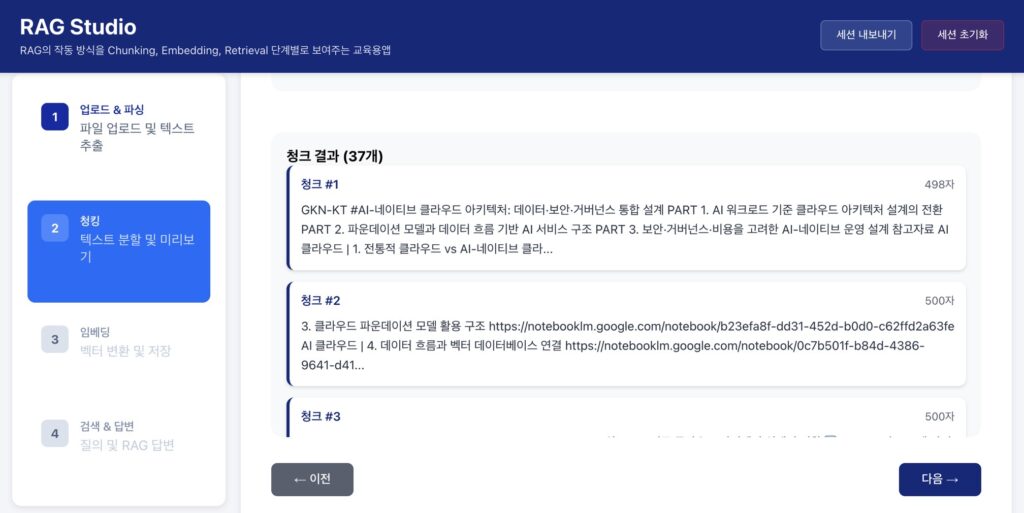
- 수집(Ingestion): 사내 문서, DB 등 소스에서 데이터 확보.
- 전처리 및 청킹(Chunking): 컨텍스트 윈도우 한계를 고려하여 텍스트 분할 및 노이즈 제거.
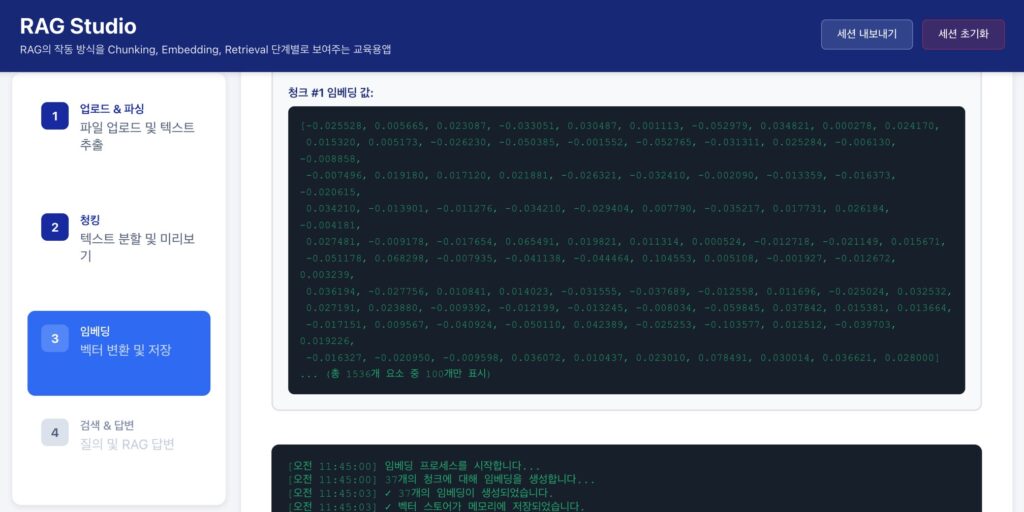
- 임베딩(Embedding): 데이터를 기계가 이해하는 숫자 벡터로 변환.
- 벡터 DB 저장: 유사도 기반 검색을 위해 의미 단위로 좌표값 저장.
- 검색 및 생성: 질문과 관련된 정보를 검색하여 LLM에 ‘참고 자료’로 제공.
4. 보안, 거버넌스 및 운영 전략
4.1 토큰 이코노미와 비용 통제
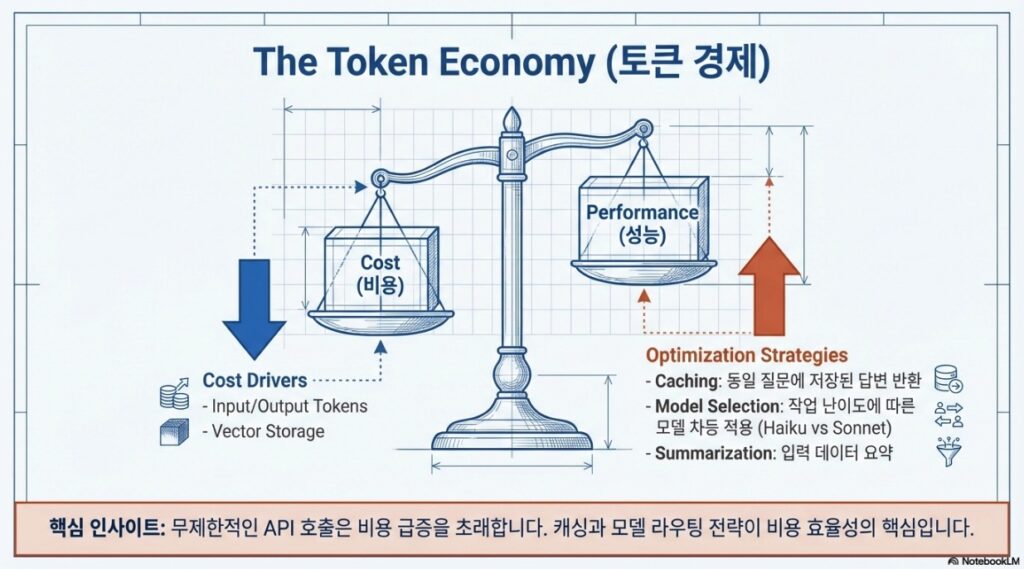
무제한적인 API 호출은 비용 급증을 초래하므로 다음과 같은 통제 기법이 필수적입니다.
- 호출 빈도 제어: 불필요한 호출을 줄이는 캐싱 전략.
- 데이터 입력 범위 통제: 프롬프트에 포함되는 데이터 양 조절 및 데이터 요약 전송.
- 모델 선택 기준: 고성능 모델(비용 높음)과 경량 모델(속도 빠름) 간의 트레이드오프 분석.
4.2 보안 내재화 (Flow Security)
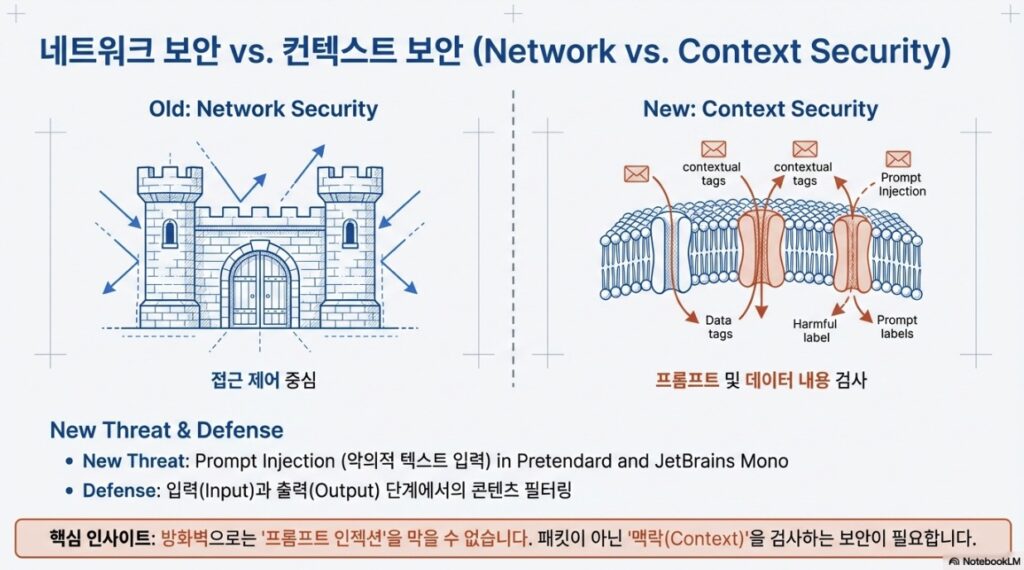
보안은 인프라 경계가 아닌 데이터 흐름 속에서 설계되어야 합니다.
- 민감 정보 필터링: PII(개인식별정보) 등이 모델로 넘어가지 않도록 사전 마킹 및 필터링 처리.
- 접근 제어(ACL): 사용자 권한에 따른 검색 가능 데이터 범위 제한.
- 감사(Audit): 누가 어떤 데이터를 검색하고 활용했는지 추적 가능한 로그 구조 마련.
결론: 아키텍트 체크리스트 (AI-네이티브 설계를 위한 질문)
성공적인 AI 도입을 위해 설계 단계에서 다음 네 가지 질문에 답할 수 있어야 합니다.
- Workload Definition: 서비스가 추론, 학습, 에이전트 중 어디에 중점을 두는가?
- Data Gravity: 데이터가 어디에 있으며, 모델이 데이터가 있는 곳으로 이동하고 있는가?
- Flow Security: 보안 검사가 인프라 경계가 아닌 데이터 흐름 속에 내재화되어 있는가?
- Cost Architecture: 비용 제약 조건이 모델 라우팅 설계에 반영되어 있는가?
참고자료 다운로드
기본교재
- 기본교재 | AI 클라우드 서비스 도입 및 기획 (PDF, 90p, 58MB, 열람 시 암호 필요)
지금은 다운로드 기간이 아닙니다. - 다운로드 | AI 클라우드 아키텍처 워크로드 비교표
https://docs.google.com/spreadsheets/d/1tT12f2Ezc2dM_ybmMHR9K0x62ugwvth98YYGltiFawg/edit?usp=sharing
실습도구
AIGrape | GPT, Gemini, Claude, Perplexity 통합 플랫폼
https://www.aigrape.net/
Colab Notebook | 클라우드 환경에서 Gemini Pro 연결, 설정, 활용하기
https://colab.research.google.com/drive/18P4RYOy_UIdIrk7qXeQIsh6aqywBfhNq?usp=sharing