원제: A SURVEY OF PROMPT ENGINEERING METHODS IN LARGE LANGUAGE MODELS FOR DIFFERENT NLP TASKS
링크드인에서 KAIST 이재현 선생님이 공유하신 유용한 자료를 만났습니다. 프롬프트는 접근성이 낮은 동시에 높다고 할 수 있는, LLM 질의 기법이라고 할 수 있겠는데요, 전문성 없이 물어도 나름 괜찮은 수준의 답을 얻을 수 있지만, 약간의 전문성을 갖추고 질문을 하면 훨씬 대단한 수준의 답을 얻을 수 있다고 생각합니다.
KAIST 이재현 선생님이 공유하신 뉴욕대 컴퓨터과학부 Vatsal, Dubey 교수님의 자료는 좋은 질문을 하기 위한 중요한 사전 지식이자, 챗GPT 등 LLM 기초 모델과 좀 더 높은 수준에서 상호작용하기 위한 단서가 될 듯 합니다.
조만간 쉽고도 어려운 질문 목록을 준비해서 ‘그냥’ 물을 때와 ‘나름 준비된 상태에서’ 물을 때 답이 얼마나 달라질 수 있는지 확인해보고 싶습니다.
논문 공저자
- Shubham Vatsal (sv2128@nyu.edu)
- Harsh Dubey (hd2225@nyu.edu)
- Department of Computer Science NewYork University, CIMS NewYork, USA / 24 Jul 2024 / arXiv:2407.12994v2 [cs.CL]
논문 초록 (Gemini에서 번역)
대규모 언어 모델(LLM)은 다양한 자연어 처리(NLP) 작업에서 괄목할 만한 성능을 보여주었습니다.
Large language models (LLMs) have shown remarkable performance on many different Natural Language Processing (NLP) tasks.
프롬프트 엔지니어링은 다양한 NLP 작업에서 LLM의 기존 능력을 더욱 향상시켜 상당한 성능 향상을 달성하는 데 핵심적인 역할을 합니다.
Prompt engineering plays a key role in adding more to the already existing abilities of LLMs to achieve significant performance gains on various NLP tasks.
프롬프트 엔지니어링은 LLM으로부터 지식을 체계적으로 이끌어내기 위해 프롬프트라고 하는 자연어 지시문을 작성하는 것을 필요로 합니다. 이전의 최첨단(SoTA) 모델과 달리, 프롬프트 엔지니어링은 주어진 NLP 작업에 따라 광범위한 매개변수 재학습이나 미세 조정을 필요로 하지 않으며, LLM에 내장된 지식만을 활용합니다.
Prompt engineering requires composing natural language instructions called prompts to elicit knowledge from LLMs in a structured way. Unlike previous state-of-the-art (SoTA) models, prompt engineering does not require extensive parameter re-training or fine-tuning based on the given NLP task and thus solely operates on the embedded knowledge of LLMs.
또한, LLM 애호가들은 기본적인 자연어 대화 교환 또는 프롬프트 엔지니어링을 통해 LLM의 지식을 지능적으로 추출할 수 있으므로, 깊이 있는 수학적 머신 러닝 배경 지식이 없는 사람들도 LLM을 실험할 수 있습니다.
Additionally, LLM enthusiasts can intelligently extract LLMs’ knowledge through a basic natural language conversational exchange or prompt engineering, allowing more and more people even without deep mathematical machine learning background to experiment with LLMs.
지난 2년 동안 프롬프트 엔지니어링이 인기를 얻으면서 연구자들은 LLM에서 정보 추출의 정확도를 향상시키기 위해 프롬프트 설계와 관련된 수많은 엔지니어링 기술을 개발했습니다. 본 논문에서는 다양한 프롬프트 기법을 요약하고, 해당 기법이 사용된 다양한 NLP 작업을 기반으로 분류했습니다.
With prompt engineering gaining popularity in the last two years, researchers have come up with numerous engineering techniques around designing prompts to improve accuracy of information extraction from the LLMs. In this paper, we summarize different prompting techniques and club them together based on different NLP tasks that they have been used for.
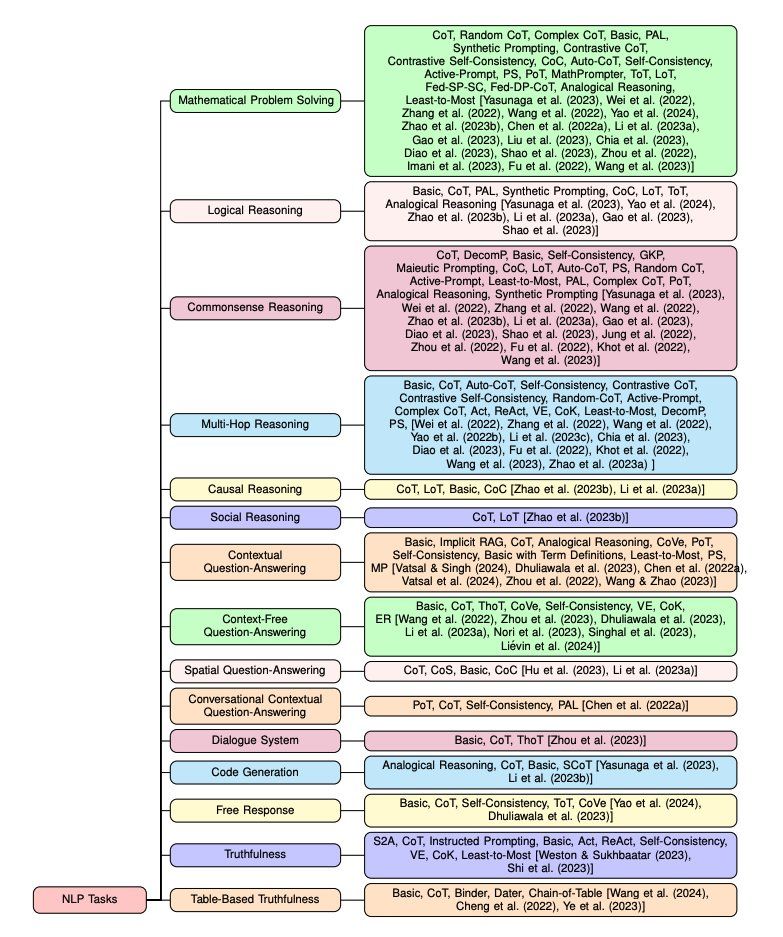
또한, 해당 NLP 작업에 속하는 다양한 데이터 세트에 대한 프롬프트 전략의 성능을 자세히 강조하고, 사용된 해당 LLM에 대해 설명하며, 분류 다이어그램을 제시하고 특정 데이터 세트에 대한 가능한 SoTA를 논의합니다.
We further granularly highlight the performance of these prompting strategies on various datasets belonging to that NLP task, talk about the corresponding LLMs used, present a taxonomy diagram and discuss the possible SoTA for specific datasets.
총 44개의 연구 논문을 읽고 조사하여, 29개의 서로 다른 NLP 작업에 대한 39개의 프롬프트 방법을 제시하며, 이 중 대부분은 지난 2년 동안 발표되었습니다.
In total, we read and present a survey of 44 research papers which talk about 39 different prompting methods on 29 different NLP tasks of which most of them have been published in the last two years.
논문 보기
https://arxiv.org/pdf/2407.12994
끝 | 감사합니다.
24.07.28 / 동준상.넥스트플랫폼