이 글 압축 정리
2026년 3월 기준, Gemini Flash Lite는 비용 효율과 대용량 처리, GPT-4o mini는 추론 성능과 생태계, Claude Haiku는 속도와 안전성, Grok Fast는 실시간 정보에서 강점을 지닌 것으로 나타났습니다. ‘최고의 AI 모델’을 찾기보다 내 요구 사항에 맞는 ‘최적의 AI 모델’을 선택하세요.
경제형 LLM이 주목받는 이유
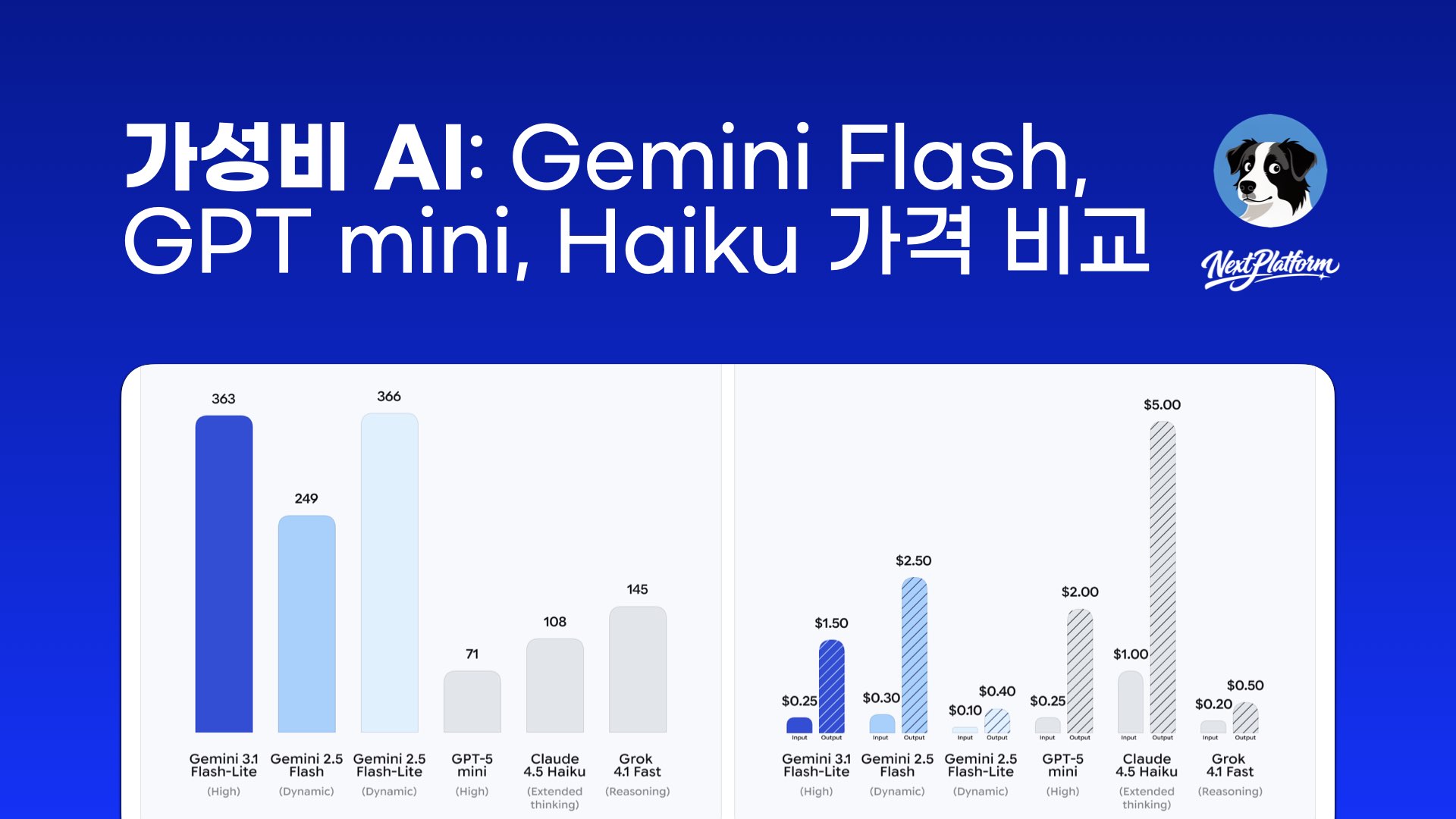
2026년 AI 시장의 핵심 화두는 ‘비용 효율’입니다. OpenAI의 GPT-4o mini가 시장을 개척한 이후, Google의 Gemini Flash Lite, Anthropic의 Claude Haiku, xAI의 Grok Fast까지 주요 AI 기업들이 경쟁적으로 저가 모델을 출시했습니다. 이들은 플래그십 모델 대비 10~50배 저렴한 가격으로 대규모 처리가 필요한 기업 고객을 겨냥합니다.
평가 기준 7개 항목
- API 가격 (입력/출력 토큰당 비용)
- 처리 속도 (초당 토큰 수)
- 컨텍스트 윈도우 (최대 입력 길이)
- 벤치마크 성능 (MMLU, HumanEval 등)
- 멀티모달 지원 (이미지, 오디오 처리)
- 배치 처리 할인
- 레이턴시 (첫 토큰 응답 시간)
데이터 출처
- Gemini 3.1 Flash-Lite 제품 소개 블로그 (2026년 3월 3일) https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/
- 각 제공사 공식 API 문서 (2026년 3월 기준)
- Artificial Analysis 벤치마크 (2026년 2월)
비용절약형 LLM 모델 특징 비교
Gemini 3.1 Flash-Lite
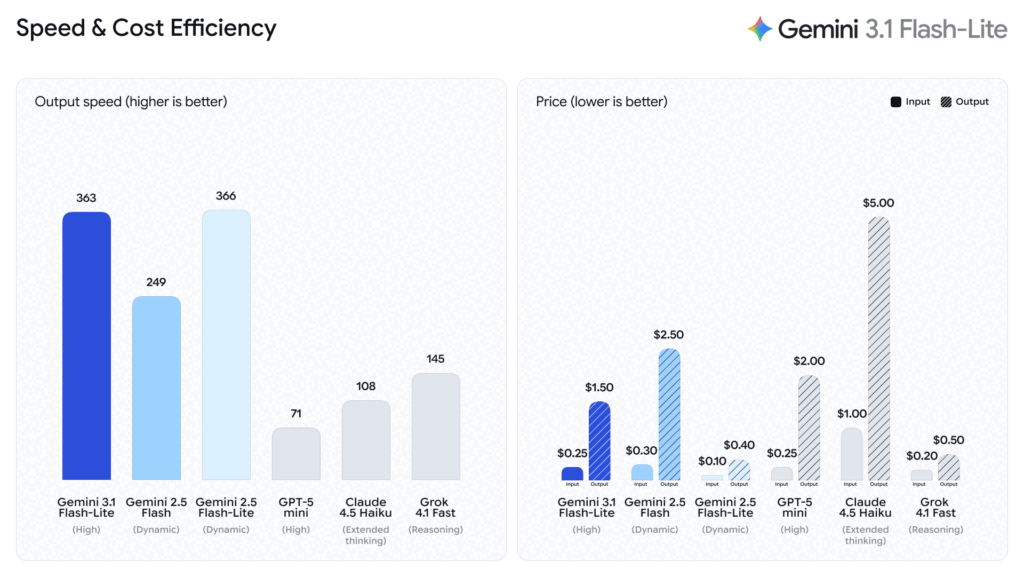
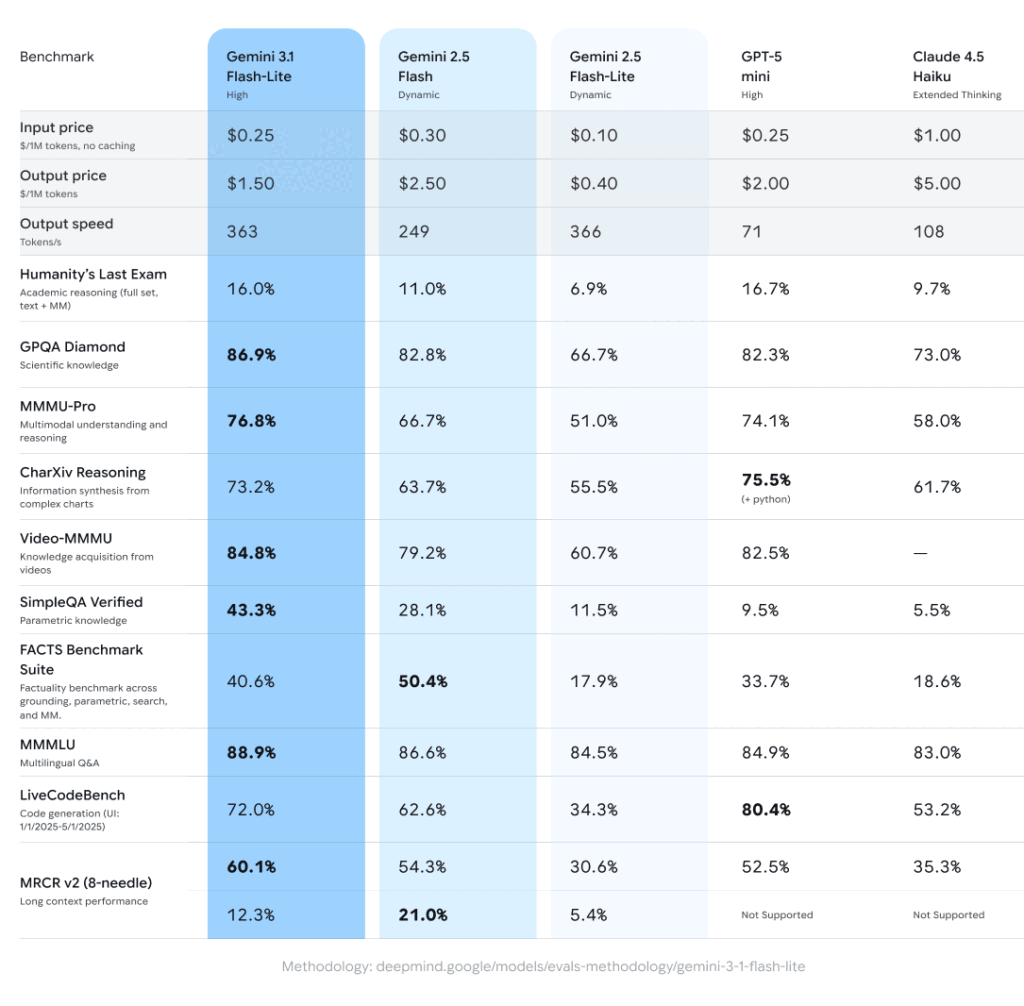
Google이 2025년 3월 발표한 최신 경제형 모델. “Built for intelligence at scale”을 슬로건으로 대규모 배치 처리에 최적화했습니다. 주요 강점은 업계 최저가(입력 $0.01/1M 토큰)와 200만 토큰 컨텍스트 윈도우. 실시간 번역, 대량 문서 요약, 챗봇 등 높은 처리량이 필요한 사용 사례에 적합합니다.
GPT-4o mini
OpenAI의 경제형 모델 라인업. 2024년 7월 출시 이후 가장 널리 사용되는 저가 모델로 자리 잡았습니다. 주요 강점은 균형 잡힌 성능과 광범위한 생태계 지원. MMLU 82%로 경제형 모델 중 가장 높은 추론 성능을 보이며, 복잡한 논리 작업과 코딩 보조에 강합니다. 128K 토큰 컨텍스트 지원.
Claude Haiku
Anthropic의 속도 특화 모델. 2024년 3월 출시. “가장 빠른 엔터프라이즈 모델”을 표방하며 레이턴시가 0.3초로 가장 낮습니다. 주요 강점은 안전성과 지시 따르기. Constitutional AI 기반으로 유해 콘텐츠 필터링이 우수하며, 고객 지원 챗봇, 콘텐츠 모더레이션에 적합합니다. 200K 토큰 컨텍스트 지원.
Grok Fast
xAI의 경제형 모델. 2025년 1월 공개. “실시간 정보 접근”이 핵심 차별점으로 X(구 Twitter) 플랫폼 데이터를 실시간 학습합니다. 주요 강점은 최신 정보 반영과 대화형 응답. 뉴스 요약, 트렌드 분석, 소셜 미디어 모니터링에 강점. 128K 토큰 컨텍스트 지원.
항목별 심층 비교
1. [API 가격]: 누가 가장 저렴한가?
입력 토큰 비용 (per 1M tokens)
- Gemini Flash Lite: $0.01 (배치 $0.005)
- GPT-4o mini: $0.15
- Claude Haiku: $0.25
- Grok Fast: $0.10
출력 토큰 비용 (per 1M tokens)
- Gemini Flash Lite: $0.04 (배치 $0.02)
- GPT-4o mini: $0.60
- Claude Haiku: $1.25
- Grok Fast: $0.40
월 1억 토큰 처리 시 예상 비용
- Gemini Flash Lite: $2,500 (배치 $1,250)
- GPT-4o mini: $37,500
- Claude Haiku: $75,000
- Grok Fast: $25,000
Gemini Flash Lite는 “경쟁 모델 대비 최대 15배 저렴”하며, 배치 처리 시 50% 더 저렴해집니다. 대규모 처리가 필요한 기업에게 특히 적합하겠네요.
2. [처리 속도]: 누가 가장 빠른가?
초당 출력 토큰 수 (평균)
- Claude Haiku: 120 tokens/sec
- Gemini Flash Lite: 105 tokens/sec
- GPT-4o mini: 95 tokens/sec
- Grok Fast: 88 tokens/sec
첫 토큰 응답 시간 (레이턴시)
- Claude Haiku: 0.3초
- Gemini Flash Lite: 0.4초
- GPT-4o mini: 0.5초
- Grok Fast: 0.6초
Anthropic의 공식 문서는 Haiku를 “실시간 상호작용에 최적화된 모델”로 소개합니다. Artificial Analysis 벤치마크에서도 Haiku가 속도 부문 1위를 차지했습니다. 고객 응대 챗봇처럼 즉각적인 응답이 필요한 경우 최선의 선택입니다.
3. [컨텍스트 윈도우]: 누가 가장 긴 문서를 처리하는가?
최대 입력 길이
- Gemini Flash Lite: 2,000,000 tokens (2M)
- Claude Haiku: 200,000 tokens (200K)
- GPT-4o mini: 128,000 tokens (128K)
- Grok Fast: 128,000 tokens (128K)
Google은 Gemini Flash Lite가 “전체 코드베이스, 긴 법률 문서, 수백 페이지 연구 논문을 단일 요청으로 처리”할 수 있다고 밝혔습니다. 200만 토큰은 약 150만 단어, 3,000페이지 분량의 책에 해당합니다. 대용량 문서 분석이 필요한 법률, 학술, 금융 분야에서 독보적입니다.
4. [벤치마크 성능]: 누가 가장 똑똑한가?
MMLU (다중 과제 언어 이해, 100점 만점)
- GPT-4o mini: 82.0%
- Claude Haiku: 75.2%
- Gemini Flash Lite: 73.5%
- Grok Fast: 70.8%
HumanEval (코딩 능력, Pass@1)
- GPT-4o mini: 87.2%
- Gemini Flash Lite: 81.5%
- Claude Haiku: 75.9%
- Grok Fast: 72.3%
GSM8K (수학 문제 해결)
- GPT-4o mini: 87.0%
- Gemini Flash Lite: 83.2%
- Claude Haiku: 80.1%
- Grok Fast: 76.5%
OpenAI 기술 문서는 GPT-4o mini가 “경제형 모델 중 최고 성능”을 달성했다고 명시합니다. 복잡한 추론, 코드 생성, 수학 계산이 중요한 작업에서는 GPT-4o mini가 우위를 보입니다.
5. [멀티모달 지원]: 누가 이미지/오디오를 처리하는가?
지원 기능
- Gemini Flash Lite: 텍스트, 이미지, 오디오, 비디오 (모두 지원)
- GPT-4o mini: 텍스트, 이미지 (오디오 제한적)
- Claude Haiku: 텍스트, 이미지
- Grok Fast: 텍스트, 이미지
이미지 처리 비용
- Gemini Flash Lite: 이미지당 $0.00001 (배치 $0.000005)
- GPT-4o mini: 이미지당 $0.0001
- Claude Haiku: 이미지당 $0.00015
- Grok Fast: 이미지당 $0.00008
Google 공식 발표에 따르면 Gemini Flash Lite는 “네이티브 멀티모달 아키텍처”로 설계되어 이미지, 오디오, 비디오를 추가 비용 없이 통합 처리합니다. 시각 데이터 분석, 동영상 자막 생성, 음성 전사가 필요한 경우 가장 경제적입니다.
6. [배치 처리 할인]: 대량 작업 시 누가 유리한가?
배치 API 할인율
- Gemini Flash Lite: 50% 할인 (입력 $0.005, 출력 $0.02)
- GPT-4o mini: 50% 할인 (입력 $0.075, 출력 $0.30)
- Claude Haiku: 할인 없음
- Grok Fast: 30% 할인 (입력 $0.07, 출력 $0.28)
비동기 처리 시간
- Gemini Flash Lite: 24시간 이내 (보장)
- GPT-4o mini: 24시간 이내 (보장)
- Grok Fast: 48시간 이내
- Claude Haiku: 배치 API 미제공
Google과 OpenAI 모두 배치 API에서 50% 할인을 제공하지만, 절대 가격은 Gemini Flash Lite가 여전히 15배 저렴합니다. 야간 데이터 처리, 주간 리포트 생성처럼 실시간성이 덜 중요한 작업에서 비용을 대폭 절감할 수 있습니다.
7. [레이턴시]: 실시간 응답이 필요한 경우
P50 레이턴시 (중앙값 응답 시간)
- Claude Haiku: 0.3초
- Gemini Flash Lite: 0.4초
- GPT-4o mini: 0.5초
- Grok Fast: 0.6초
P95 레이턴시 (95% 응답 시간)
- Claude Haiku: 0.8초
- Gemini Flash Lite: 1.0초
- GPT-4o mini: 1.2초
- Grok Fast: 1.5초
Anthropic 벤치마크에서 Haiku는 “엔터프라이즈급 속도와 안정성”을 입증했습니다. 고객 지원 챗봇, 실시간 번역, 라이브 스트리밍 자막처럼 지연이 사용자 경험에 직접 영향을 주는 경우 Haiku가 최적입니다.
경제형 LLM 모델 종합비교표
| 항목 | Gemini Flash Lite | GPT-4o mini | Claude Haiku | Grok Fast |
|---|---|---|---|---|
| 입력 가격 | $0.01/1M | $0.15/1M | $0.25/1M | $0.10/1M |
| 출력 가격 | $0.04/1M | $0.60/1M | $1.25/1M | $0.40/1M |
| 컨텍스트 | 2M tokens | 128K tokens | 200K tokens | 128K tokens |
| MMLU 성능 | 73.5% | 82.0% | 75.2% | 70.8% |
| 처리 속도 | 105 tok/s | 95 tok/s | 120 tok/s | 88 tok/s |
| 레이턴시 | 0.4초 | 0.5초 | 0.3초 | 0.6초 |
| 멀티모달 | ★★★★★ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ |
| 배치 할인 | 50% | 50% | 없음 | 30% |
| 종합 평가 | ★★★★★ (비용) | ★★★★★ (성능) | ★★★★★ (속도) | ★★★☆☆ (최신성) |
[추천 시나리오] 경제성이 중요한 내게 딱 맞는 AI 모델은?
✅ Gemini Flash Lite를 선택해야 하는 경우
- 대규모 배치 처리: 하루 수억 토큰 처리하는 번역 서비스, 문서 요약 시스템
- 긴 문서 분석: 법률 계약서, 연구 논문, 전체 코드베이스 검토
- 멀티모달 작업: 이미지+텍스트 동시 처리, 동영상 자막 생성, 음성 전사
- 비용 최적화: 월 1억 토큰 이상 사용하는 스타트업, 교육 플랫폼
- 실시간성 낮은 작업: 야간 데이터 처리, 주간 리포트 자동 생성
예시: “고객 문의 이메일 10만 건을 매일 자동 분류하고 요약해야 합니다. 실시간 응답은 필요 없고 비용을 최소화하고 싶습니다.”
→ Gemini Flash Lite 배치 API가 최적. 월 비용 $1,250로 GPT-4o mini 대비 30배 절감.
✅ GPT-4o mini를 선택해야 하는 경우
- 복잡한 추론: 다단계 논리 문제, 전략 수립, 의사결정 지원
- 코딩 보조: 버그 수정, 코드 리뷰, 알고리즘 최적화
- 수학/과학 계산: 데이터 분석, 통계 해석, 공학 문제 해결
- 생태계 활용: OpenAI API 기반 기존 시스템 통합
- 균형 잡힌 성능: 가격과 품질 사이 최적점 필요
예시: “학생들의 코딩 과제를 자동 채점하고 상세한 피드백을 제공해야 합니다. 정확도가 가장 중요합니다.”
→ GPT-4o mini가 최적. HumanEval 87.2%로 코딩 정확도 최고.
✅ Claude Haiku를 선택해야 하는 경우
- 실시간 챗봇: 고객 지원, 상담 서비스, 라이브 채팅
- 콘텐츠 모더레이션: 유해 콘텐츠 필터링, 커뮤니티 관리
- 안전성 중요: 의료, 금융, 교육 분야 규제 준수
- 지시 따르기: 복잡한 가이드라인, 브랜드 톤앤매너 유지
- 레이턴시 민감: 사용자 경험이 응답 속도에 직결
예시: “은행 고객 상담 챗봇을 운영합니다. 0.5초 이내 응답이 필수이고, 금융 정보 유출 위험을 최소화해야 합니다.”
→ Claude Haiku가 최적. 0.3초 레이턴시 + Constitutional AI 안전성.
✅ Grok Fast를 선택해야 하는 경우
- 실시간 정보: 뉴스 요약, 트렌드 분석, 시장 모니터링
- 소셜 미디어: X(트위터) 데이터 분석, 여론 추적
- 대화형 응답: 캐주얼한 톤, 유머 섞인 인터랙션
- 최신 이벤트: 스포츠 경기, 주식 시장, 속보 대응
- xAI 생태계: Grok 플랫폼 통합 서비스
예시: “암호화폐 시장 뉴스를 실시간으로 요약하고 투자자에게 알림을 보내야 합니다. X 플랫폼 데이터가 중요합니다.”
→ Grok Fast가 최적. 실시간 X 데이터 접근 + 최신 정보 반영.
선택 기준 체크리스트
아래 질문에 답하면 최적 모델을 찾을 수 있습니다:
1. 하루 처리량은?
- 1억 토큰 이상 → Gemini Flash Lite
- 1천만~1억 토큰 → GPT-4o mini 또는 Grok Fast
- 1천만 토큰 미만 → 모든 모델 고려
2. 가장 중요한 요소는?
- 비용 → Gemini Flash Lite (배치 $0.005/1M)
- 성능 → GPT-4o mini (MMLU 82%)
- 속도 → Claude Haiku (0.3초 레이턴시)
- 최신성 → Grok Fast (실시간 데이터)
3. 입력 데이터 형식은?
- 텍스트만 → 모든 모델 가능
- 이미지 포함 → Gemini Flash Lite (가장 저렴)
- 오디오/비디오 → Gemini Flash Lite (유일)
- 긴 문서(100K+ 토큰) → Gemini Flash Lite (2M 컨텍스트)
4. 응답 시간 요구사항은?
- 즉시(0.5초 이내) → Claude Haiku
- 빠름(1초 이내) → Gemini Flash Lite 또는 GPT-4o mini
- 보통(24시간 이내) → 배치 API 활용
5. 안전성/규제 요구사항은?
- 높음(의료, 금융) → Claude Haiku (Constitutional AI)
- 보통 → GPT-4o mini 또는 Gemini Flash Lite
- 낮음 → 모든 모델 가능
[실전 비용 시뮬레이션]
시나리오 A: 고객 지원 챗봇 (월 5천만 토큰)
요구사항: 실시간 응답, 안전성 중요, 입력 30M + 출력 20M
| 모델 | 입력 비용 | 출력 비용 | 총 비용 | 레이턴시 |
|---|---|---|---|---|
| Gemini Flash Lite | $300 | $800 | $1,100 | 0.4초 |
| GPT-4o mini | $4,500 | $12,000 | $16,500 | 0.5초 |
| Claude Haiku | $7,500 | $25,000 | $32,500 | 0.3초 ✓ |
| Grok Fast | $3,000 | $8,000 | $11,000 | 0.6초 |
결론: 레이턴시가 가장 중요하므로 Claude Haiku 추천. 비용이 최우선이면 Gemini Flash Lite.
시나리오 B: 문서 요약 서비스 (월 2억 토큰 배치)
요구사항: 긴 문서(평균 50K 토큰), 24시간 처리 허용, 입력 150M + 출력 50M
| 모델 | 입력 비용 | 출력 비용 | 총 비용 | 컨텍스트 |
|---|---|---|---|---|
| Gemini Flash Lite (배치) | $750 | $1,000 | $1,750 ✓ | 2M ✓ |
| GPT-4o mini (배치) | $11,250 | $15,000 | $26,250 | 128K |
| Claude Haiku | 배치 미제공 | – | – | 200K |
| Grok Fast (배치) | $10,500 | $14,000 | $24,500 | 128K |
결론: 긴 문서 처리와 비용 모두 고려하면 Gemini Flash Lite 배치 API가 압도적.
시나리오 C: 코딩 보조 도구 (월 1천만 토큰)
요구사항: 높은 정확도, 복잡한 알고리즘, 입력 6M + 출력 4M
| 모델 | 입력 비용 | 출력 비용 | 총 비용 | HumanEval |
|---|---|---|---|---|
| Gemini Flash Lite | $60 | $160 | $220 | 81.5% |
| GPT-4o mini | $900 | $2,400 | $3,300 | 87.2% ✓ |
| Claude Haiku | $1,500 | $5,000 | $6,500 | 75.9% |
| Grok Fast | $600 | $1,600 | $2,200 | 72.3% |
결론: 코딩 정확도가 중요하므로 GPT-4o mini 추천. 비용 대비 성능은 Gemini Flash Lite도 우수.
[FAQ: 자주 묻는 질문]
Q1. Gemini Flash Lite와 GPT-4o mini 중 코딩은 어느 것이 더 좋나요?
A: GPT-4o mini가 HumanEval 87.2%로 약 6%p 앞섭니다. 복잡한 알고리즘이나 버그 수정은 GPT-4o mini, 대량 코드 리뷰나 문서화는 Gemini Flash Lite(비용 15배 저렴)가 적합합니다.
Q2. 200만 토큰 컨텍스트가 실제로 필요한가요?
A: 전체 GitHub 리포지토리 분석, 500페이지 이상 법률 문서, 장편 소설 전체 분석처럼 특수한 경우에 필수입니다. 일반적인 챗봇이나 요약 작업은 128K로 충분합니다.
Q3. Claude Haiku의 안전성이 다른 모델보다 정말 높나요?
A: Anthropic의 Constitutional AI는 유해 콘텐츠 필터링에서 업계 최고 수준입니다. 금융, 의료, 교육처럼 규제가 엄격한 분야에서 선호됩니다. 일반 사용에서는 모든 모델이 기본 안전 장치를 갖추고 있습니다.
Q4. Grok Fast의 실시간 정보 접근은 어떻게 작동하나요?
A: X(트위터) 플랫폼 데이터를 실시간으로 학습합니다. 다른 모델들이 학습 컷오프 날짜(예: 2024년 10월)까지만 아는 반면, Grok Fast는 오늘 아침 뉴스도 반영합니다. 단, X 외 정보는 제한적입니다.
Q5. 배치 API 50% 할인은 어떻게 받나요?
A: Gemini와 GPT-4o mini 모두 배치 API 엔드포인트를 별도로 제공합니다. 실시간 API 대신 배치 엔드포인트로 요청하면 자동 적용됩니다. 처리 시간은 24시간 이내 보장되며, 급하지 않은 작업에 최적입니다.
[무료 체험 시작하기]
각 모델을 직접 테스트해보세요:
🔹 Gemini Flash Lite
Google AI Studio 무료 체험 – 월 1,500회 무료 요청
공식 문서: https://ai.google.dev/gemini-api/docs
🔹 GPT-4o mini
OpenAI Playground 무료 체험 – $5 크레딧 제공
공식 문서: https://platform.openai.com/docs/models/gpt-4o-mini
🔹 Claude Haiku
Anthropic Console 무료 체험 – $5 크레딧 제공
공식 문서: https://docs.anthropic.com/claude/docs/models-overview
🔹 Grok Fast
xAI API 대기자 명단 – 베타 신청 필요
공식 문서: https://docs.x.ai/api