AI Cloud Hands-on Lab: Building an AI Image Generation App with Vertex AI
핵심 요약 (Executive Summary)
이번 포스트는 Vertex AI 플랫폼을 활용하여 생성형 AI 이미지 생성 애플리케이션을 구축하는 과정과 주요 기술적 요소를 정리한 실습 가이드입니다.
- 플랫폼 및 도구: Google Cloud의 Vertex AI SDK를 사용하여 클라우드 기반 AI 서비스에 연결하며,
gemini-2.5-flash-image모델을 핵심 엔진으로 활용 - 핵심 프로세스: 텍스트 프롬프트 입력, 모델 호출(
generate_content), 응답 데이터 처리(이미지 추출 및 저장)로 이어지는 워크플로우를 구현 - 시스템 안정성: API 호출 제한(Quota exhaustion) 및 리소스 고갈 상황에 대비하여 지수 백오프(Exponential Backoff) 기반의 재시도 로직을 포함
- 주요 기능: 텍스트를 기반으로 한 고품질 이미지 생성 및 SynthID 워터마크 자동 삽입 기능을 지원
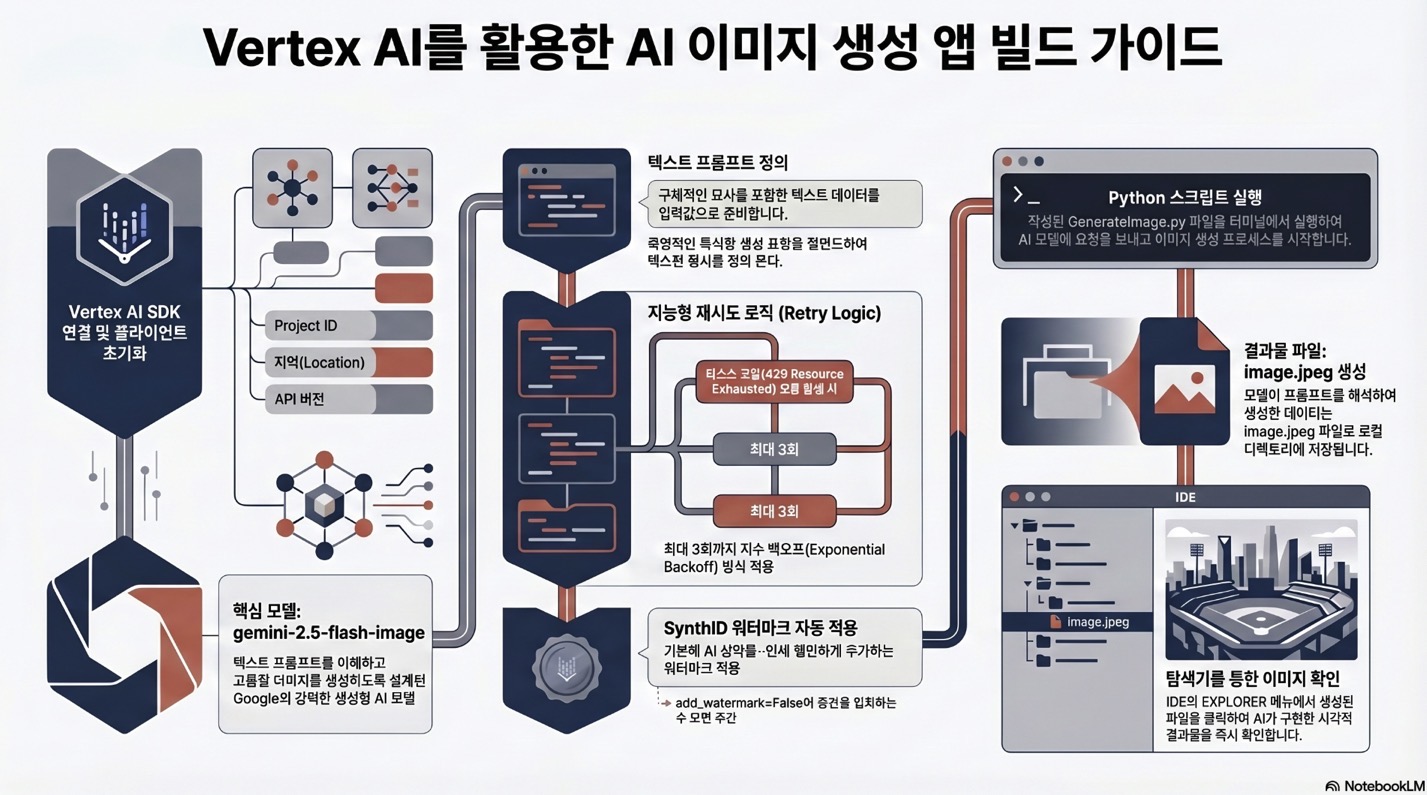
| 실습 단계 | 주요 목표 | 사용 도구 및 SDK | 핵심 코드 구성 요소 |
| 1. 환경 준비 및 파일 생성 | Vertex AI SDK를 사용하여 클라우드 AI 플랫폼에 연결하고 실습을 위한 Python 파일 준비 | Google Cloud IDE, Vertex AI SDK, google.genai, gcloud SDK | genai.Client 초기화 (프로젝트 및 지역 설정), File > New File을 통한 파일 생성 |
| 2. 코드 작성 및 모델 설정 | Gemini 모델을 호출하고 이미지 생성을 위한 프롬프트 구성 | Python 3, google.genai.types (HttpOptions 등), PIL (Image) | client.models.generate_content 호출, 프롬프트 입력(“Create an image of a cricket ground…”), 재시도 로직(Retry logic) |
| 3. 애플리케이션 실행 및 결과 확인 | 스크립트를 실행하여 AI가 생성한 이미지를 추출하고 로컬 디렉토리에 저장 | Terminal, Python 3 Interpreter, Explorer | part.as_image()를 통한 이미지 변환, image.save(“image.jpeg”)를 통한 파일 저장 |
1. 시스템 아키텍처 및 연결 설정
Vertex AI는 Google Cloud의 대규모 생성형 AI 모델을 테스트, 조정 및 배포할 수 있는 통합 플랫폼이다. 애플리케이션 구축을 위한 초기 단계는 다음과 같은 기술적 구성을 포함한다.
1.1 SDK 및 환경 초기화
- Vertex AI SDK: Python 환경에서
google.genai라이브러리를 통해 AI 모델과 상호작용한다. - 인증 및 구성: 클라이언트 인스턴스 생성 시 프로젝트 ID(
qwiklabs-gcp-00-e1ceed4a2bcc), 지역(us-central1), API 버전(v1) 등의 매개변수를 설정하여 대상 서비스에 연결한다. - 로깅 시스템:
google.cloud.logging을 통합하여 애플리케이션의 작동 상태 및 오류를 추적한다.
1.2 클라이언트 설정 요약
| 항목 | 설정 내용 |
| 모델명 | gemini-2.5-flash-image |
| 플랫폼 여부 | Vertex AI 기반 (vertexai=True) |
| API 옵션 | HttpOptions(api_version="v1") |
2. 이미지 생성 워크플로우 분석
애플리케이션의 핵심 로직은 사용자의 텍스트 입력을 시각적 결과물로 변환하는 과정을 포함한다.
2.1 프롬프트 처리 및 모델 호출
사용자가 입력한 텍스트 프롬프트(예: “Create an image of a cricket ground in the heart of Los Angeles”)는 모델의 generate_content 메서드에 전달된다. 모델은 이 텍스트의 맥락을 파악하여 이미지 데이터를 생성한다.
2.2 응답 데이터 처리 메커니즘
모델의 응답(response)은 멀티모달 특성을 가질 수 있으며, 다음과 같은 조건부 로직을 통해 처리된다.
- 텍스트 응답 확인:
part.text가 존재할 경우 이를 출력한다. - 이미지 데이터 추출:
part.inline_data가 포함된 경우as_image()메서드를 호출하여 이미지 객체로 변환한다. - 파일 저장: 변환된 이미지는
image.jpeg와 같은 로컬 파일 형태로 저장되어 최종 사용자에게 제공된다.
소스 코드의 주요 내용
- The code snippet is loading an AI model (
flash-image-model-id) on Vertex AI. - The code calls the
generate_contentmethod of the loaded Gemini model. - The input to the method is a text prompt.
- The code uses Gemini’s ability to understand the text prompt and use it to build an AI Image.
소스 코드: GenerateImage.py
import time
from google import genai
from google.genai import types
from PIL import Image
from google.genai.types import HttpOptions, ModelContent, Part, UserContent
from google.cloud import logging as gcp_logging
from google.genai.errors import ClientError
# ------ Below cloud logging code is for Qwiklab's internal use, do not edit/remove it. --------
# Initialize Google Cloud logging
gcp_logging_client = gcp_logging.Client()
gcp_logging_client.setup_logging()
client = genai.Client(
vertexai=True,
project='"project-id"',
location='"REGION"',
http_options=HttpOptions(api_version="v1")
)
prompt = (
"Create an image of a cricket ground in the heart of Los Angeles",
)
# Configuration for retry logic
MAX_RETRIES = 3
INITIAL_DELAY = 2
for attempt in range(MAX_RETRIES + 1):
try:
response = client.models.generate_content(
model="flash-image-model-id",
contents=[prompt],
)
# Original processing logic
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("image.jpeg")
print("Status: Image saved as image.jpeg")
# --- Success Block ---
print("Success: Content generation and processing completed successfully.")
break
except ClientError as e:
if "429" in str(e) or "RESOURCE_EXHAUSTED" in str(e):
if attempt < MAX_RETRIES:
delay = INITIAL_DELAY * (2 ** attempt)
print(f"Warning: Resource exhausted (429). Retrying in {delay} seconds... (Attempt {attempt + 1}/{MAX_RETRIES})")
time.sleep(delay)
else:
print("I am currently experiencing high demand due to quota exhaustion. Please wait for a while and try again.")
finally:
# Verify if the process concluded without a response object being created
if 'response' not in locals() and attempt == MAX_RETRIES:
print("Final Status: Process terminated unsuccessfully.")3. 주요 기능 및 모델 특성
3.1 SynthID 워터마크
- 자동 삽입: 기본적으로 생성된 모든 이미지에는 SynthID 워터마크가 추가되어 생성형 AI로 제작된 콘텐츠임을 나타낸다.
- 선택적 비활성화:
add_watermark=False파라미터를 사용하여 워터마크를 제거할 수 있으나, 시드(Seed) 값과 워터마크 기능을 동시에 사용할 수는 없다.
3.2 이미지 생성 성능
gemini-2.5-flash-image 모델은 텍스트 프롬프트에 대한 깊은 이해를 바탕으로 복잡한 배경(예: 로스앤젤레스 중심부의 크리켓 경기장)을 정교하게 시각화하는 능력을 보유하고 있다.
4. 예외 처리 및 안정성 확보
대규모 AI 서비스 운영 시 발생할 수 있는 리소스 제한 문제를 해결하기 위해 고도화된 오류 처리 로직이 적용되었다.
4.1 재시도 로직 (Retry Logic)
리소스 고갈(HTTP 429 오류) 또는 할당량 초과(RESOURCE_EXHAUSTED) 발생 시 시스템은 즉시 중단되지 않고 재시도를 수행한다.
- 최대 재시도 횟수: 3회 (
MAX_RETRIES = 3) - 대기 시간 전략: 초기 2초(
INITIAL_DELAY)에서 시작하여 재시도할 때마다 대기 시간을 2배씩 늘리는 지수 백오프 방식을 채택한다.
4.2 오류 코드 대응
| 오류 유형 | 시스템 대응 |
| 429 / RESOURCE_EXHAUSTED | 지정된 횟수만큼 재시도 후 실패 시 “수요 과다” 메시지 출력 |
| 기타 ClientError | 예외 발생 시 프로세스 종료 및 실패 상태 기록 |
결론
이번 실습을 통해 Vertex AI를 통한 이미지 생성 애플리케이션의 설계와 구현 방식을 함께 알아봤습니다.
- Gemini 모델의 생성 능력과 Vertex AI SDK의 유연한 연결성, 그리고 안정적인 오류 처리 메커니즘이 결합되어 실무 환경에서 활용 가능한 수준의 AI 애플리케이션 구축 방법 이해
- 개발자는 프롬프트 엔지니어링을 통해 모델의 성능을 극대화할 수 있으며, 워터마크 관리 기능을 통해 생성물의 목적에 맞는 세부 설정 가능